



In the race to AI maturity, computer vision stands out as one of the most transformative technologies, powering everything from autonomous vehicles and medical imaging to smart factories and eCommerce personalization. But behind every high-performing vision model is one critical foundation: precise image annotation.
And one of the most pivotal early decisions? Image classification vs. object detection. These aren’t interchangeable. They solve different visual challenges, require distinct annotation approaches, and drive different business outcomes. Choosing the wrong method can derail your entire pipeline, leading to mislabelled data, wasted budget, and inaccurate models.
As an AI-focused IT outsourcing company, we regularly guide clients across sectors in making this call – where to classify, where to detect, and how to scale smartly.
In this article, we will unpack the core differences, ideal use cases, and annotation strategies for each – image classification vs object detection, with a focus on real-world impact and long-term scalability.
Image Classification: Definition, Types, How It Works & Use Cases
What is image classification?
Image classification is the process of assigning a single label or category to an entire image based on its content.
Think of image classification as teaching a computer to answer the question: “What is the primary subject of this image?” When presented with a photograph of a golden retriever playing in a park, a well-trained image classification model would confidently respond with the label “dog” – focusing on identifying the most prominent subject within the frame.
Another example, say you feed an image of a road into your model, and it tells you: “This is a picture of a car.” The model doesn’t tell you where the car is or whether there’s also a person or traffic light present – only that the most relevant label is “car”.

For an in-depth overview of annotation types, methodologies, and practical implementation across industries, see our guide on what is data annotation: types, techniques & best practices.
Types of image classification
Modern image classification systems typically employ one of two primary approaches:
Single-label classification
This traditional approach assigns one definitive category to each image. For instance, an image would be classified as either “cat” or “dog” but never both simultaneously. This method works exceptionally well for applications requiring clear-cut categorization.
Multi-label classification
This advanced approach recognizes that real-world images often contain multiple relevant categories. An outdoor scene might simultaneously be labeled as “mountain,” “forest,” “lake,” and “sunset,” providing richer contextual information for downstream applications.
How image classification works
Image classification models typically use convolutional neural networks (CNNs) to extract hierarchical features such as edges, textures, shapes from images. The model learns from a large dataset of labeled images, identifying patterns that correspond to different classes. The output is a single class label per image, reflecting the dominant object or scene.
How image classification works: Key steps in brief
- Input image: The model receives the image as pixel data.
- Feature extraction: CNN layers detect basic features like edges and textures.
- Hierarchical learning: Deeper layers combine simple features into complex shapes.
- Classification: Fully connected layers analyze features to predict a single label.
- Output: The model assigns the most probable class to the image.
- Training: The model improves by learning from labeled examples through backpropagation.
Summary: Image classification key features
| Aspect | Details |
| Primary function | Assigns single category/label to entire image |
| Output type | One class label per image |
| Complexity level | Moderate – focuses on overall image content |
| Training requirements | Labeled images with class categories |
| Processing speed | Generally faster than object detection |
Object Detection: Definition, How It Works & Use Cases
What is object detection?
While image classification excels at identifying what’s in an image, object detection takes visual understanding to the next level by answering both “what” and “where.” This sophisticated technology not only identifies multiple objects within a single image but also precisely locates each object by drawing bounding boxes around them.
Object detection represents a significant leap in complexity compared to image classification, as it must simultaneously solve two challenging problems: classification (what objects are present) and localization (where exactly they’re located within the image).

How object detection works
Object detection systems typically employ sophisticated neural network architectures designed to handle the dual requirements of classification and localization:
Region-based approaches
Technologies such as Faster R-CNN first generate potential object regions, then classify and refine the locations of objects within those regions. This approach tends to be highly accurate but computationally intensive.
Single-shot detection
Modern frameworks like YOLO (You Only Look Once) and SSD (Single Shot MultiBox Detector) perform detection in a single pass through the network, offering faster processing speeds that enable real-time applications.
Summary: Object detection key features
| Feature | Specification |
| Primary function | Identifies and localizes multiple objects per image |
| Output type | Multiple class labels with bounding box coordinates |
| Complexity level | High – requires classification and localization |
| Training data | Images with class labels and precise annotations |
| Processing requirements | More computationally intensive |
| Precision level | Pixel-level accuracy for object boundaries |
Image Classification vs Object Detection: Key Differences
Understanding the fundamental differences between image classification and object detection is essential for selecting the right approach for your specific business needs.

Task complexity and computational requirements
Image classification operates with a singular focus: determining the primary category of an entire image. This streamlined approach results in:
- Lower computational requirements
- Faster processing speeds
- Simpler model architectures
- Reduced training data requirements
Object detection manages multiple complex tasks simultaneously:
- Identifying various objects within a single image
- Determining precise locations for each detected object
- Higher computational overhead
- More sophisticated neural network architectures
Output formats and information richness
The fundamental difference in output formats reflects each technology’s distinct purpose:
Image classification output: A single label with confidence scores
- Example: “Car (94% confidence)”
- Suitable for: Content categorization, basic recognition tasks
Object detection output: Multiple objects with location coordinates
- Example: “Car (x: 150, y: 200, width: 300, height: 250, confidence: 94%)”
- Suitable for: Spatial analysis, interactive applications, autonomous systems
Training data and annotation requirements
The complexity difference extends to the type and volume of training data required:
Image classification requires straightforward labeling where each image receives one primary category label. This makes data annotation relatively simple and cost-effective.
Object detection demands precise bounding box annotations for every object of interest within each image. This detailed annotation process requires specialized expertise and significantly more time investment, making professional image annotation services essential for most enterprise implementations.
Use cases
| Industry/ Application | Image classification use cases | Object detection use cases |
| Manufacturing & quality control | Detect defective products, classify materials, sort items on assembly lines | Detect and locate defects, identify parts on conveyor belts for sorting and inspection |
| Healthcare & medical imaging | Classify medical images (X-rays, MRIs) for disease diagnosis, skin lesion classification | Detect and localize tumors, abnormalities, or specific anatomical features for treatment planning |
| Agriculture | Crop health monitoring, weed detection, fruit ripeness classification, yield estimation | Detect pests, localize diseased plants or weeds for targeted treatment |
| Automotive | Classify objects detected by vehicle cameras (traffic signs, pedestrians), driver behavior analysis | Detect and locate pedestrians, vehicles, obstacles for autonomous driving and safety systems |
| Retail & eCommerce | Product recognition, visual search, customer behavior analysis, inventory categorization | Detect product placement, count items on shelves, monitor customer interactions |
| Security & surveillance | Facial recognition, scene classification, identifying persons of interest | Detect and track individuals, suspicious objects, or activities in real-time video feeds |
| Content moderation | Classify images as safe or NSFW to filter inappropriate content | Detect specific objectionable objects or scenes within images or videos |
Summary: Image classification vs object detection key differences
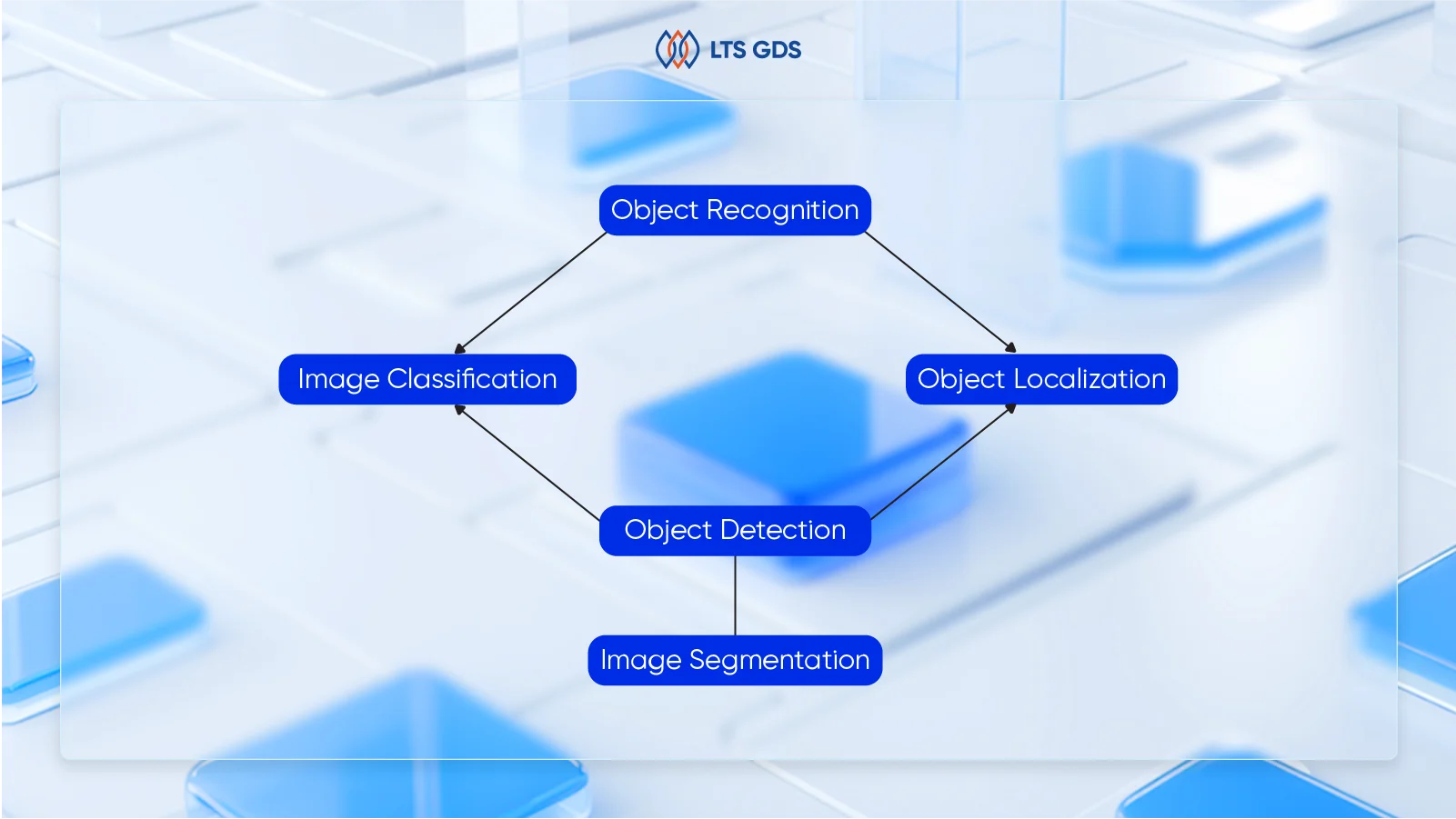
| Aspect | Image classification | Object detection |
| Task | Assign a label to the entire image | Identify and locate multiple objects with bounding boxes |
| Output | Single class label per image | Multiple class labels and bounding boxes per image |
| Complexity | Simpler; focuses on the main subject | More complex; involves classification and localization |
| Annotation type | Image-level labels | Bounding box annotations |
| Use cases | Photo organization, medical diagnosis | Autonomous vehicles, surveillance, retail analytics |
| Computational cost | Lower | Higher due to localization and multiple object handling |
| Model architectures | CNNs | Faster R-CNN, YOLO, SSD |
| Evaluation metrics | Accuracy, precision, recall | Intersection over Union (IoU), mean Average Precision (mAP) |
Image Classification vs Object Detection: Common Ground
While image classification and object detection serve different purposes in computer vision, they share several important commonalities, especially in their underlying technologies and workflows. In many real-world applications, the lines between image classification and object detection naturally blur, and the most advanced computer vision systems often integrate both to deliver richer, more contextual insights.
| Aspect | Image classification | Object detection | Similarities |
| Core technology | Uses Convolutional Neural Networks (CNNs) to extract features from images. | Also relies on CNNs for feature extraction, often combined with region proposal networks. | Both use CNN-based deep learning architectures for hierarchical feature learning. |
| Feature extraction | Extracts high-level features like edges, textures, and shapes to classify the entire image. | Extracts similar features to identify and localize multiple objects within an image. | Feature extraction process is fundamentally similar in both tasks. |
| Learning paradigm | Supervised learning with labeled images. | Supervised learning with images labeled with bounding boxes and class labels. | Both require annotated datasets and use supervised learning to train models. |
| Data preprocessing | Applies resizing, normalization, and augmentation to improve model robustness. | Uses similar preprocessing techniques to prepare training data. | Preprocessing pipelines are largely shared between the two tasks. |
| Application domains | Used in healthcare, retail, automotive, and more for categorizing images. | Used in autonomous driving, surveillance, retail analytics, and more for detecting objects. | Both contribute to image understanding and have wide-ranging industry applications. |
| Model training | Requires large labeled datasets to learn discriminative features. | Requires larger and more detailed datasets with bounding box annotations. | Training involves iterative optimization (e.g., backpropagation) to minimize errors. |
| Output format | Produces a single label per image. | Produces multiple labels with bounding boxes per image. | Both output class predictions, differing mainly in granularity and localization. |
Summary: Image classification vs object detection similarities
- Deep learning backbone: Both tasks heavily depend on CNNs to automatically learn features from raw images, eliminating manual feature engineering.
- Supervised learning: They rely on labeled data to train models that can generalize to new images.
- Image understanding: Both aim to interpret visual content, with classification focusing on the overall image and detection focusing on individual objects.
- Preprocessing and training: Share many preprocessing steps and training methodologies, such as data augmentation and gradient-based optimization.
- Industry use cases: Both are widely applied across industries like healthcare, automotive, retail, and security to solve complementary problems.
Choosing The Right Approach: Image Classification vs Object Detection
Selecting between image classification and object detection isn’t always straightforward. The optimal choice depends on your specific business requirements, technical constraints, and long-term objectives.
When image classification excels
Primary goal: Identify the main subject or overall content of an image without needing to know the exact location of objects.
Use cases: Content tagging, medical image diagnosis, quality control, and scenarios where a single label per image suffices.
Advantages:
- Simpler models and faster training times.
- Requires only image-level labels, reducing annotation effort and costs.
- Lower computational requirements, enabling deployment on edge devices or with limited resources.
Limitations:
- Cannot detect or localize multiple objects in one image.
- Less informative for applications requiring spatial awareness.
When object detection becomes essential
Primary goal: Identify and localize multiple objects within an image by predicting bounding boxes and class labels for each object.
Use cases: Autonomous driving (detecting pedestrians, vehicles), surveillance, retail analytics (product placement), robotics, and any application needing spatial context.
Advantages:
- Provides detailed scene understanding by locating objects.
- Supports multiple object classes and instances per image.
Limitations:
- More complex models require extensive annotated data with bounding boxes.
- Higher computational cost and longer training times.
- Requires more powerful hardware, often GPUs, for both training and inference.
Insights
- Hybrid approaches: Some applications benefit from combining both techniques. For example, image classification can quickly filter images before applying object detection for detailed analysis.
Also, modern AI systems increasingly integrate object detection with advanced semantic segmentation and instance segmentation techniques. This multi-layered approach enables machines to understand not just what objects are present and where they’re located, but also their precise shapes, relationships, and contextual significance.
For businesses interested in implementing comprehensive visual AI solutions, understanding these 3 types of image segmentation technologies becomes crucial for making informed architectural decisions.
- Annotation budget: If annotation resources are limited, image classification offers a cost-effective entry point. Conversely, investing in detailed annotations for object detection pays off in applications where localization is critical.
- Scalability: Object detection models often require ongoing tuning and retraining to maintain accuracy across diverse environments, while classification models can be simpler to maintain.
- Client needs: Understanding the client’s business goals and operational constraints is key to recommending the most appropriate approach.
Summary: When to choose image classification vs object detection
| Aspect | Image classification | Object detection |
| Task | Assign a single label to the entire image | Detect and localize multiple objects with bounding boxes |
| Output | One class label per image | Multiple class labels + bounding box coordinates |
| Annotation | Image-level labels only | Requires bounding box annotations |
| Model complexity | Generally simpler | More complex; combines classification and localization |
| Computational cost | Lower | Higher |
| Use cases | Image tagging, medical imaging, quality control | Autonomous driving, surveillance, retail analytics |
| Training data | Labeled images with class/category | Labeled images with class/category + bounding boxes |
| Inference speed | Faster, suitable for real-time on limited hardware | Slower, requires optimization for real-time use |
Technical Considerations: Implementation Best Practices
Crafting high-performing image classification and object detection systems requires engineering the entire pipeline – data, models, infrastructure, and feedback loops – to serve real-world demands with precision and agility. Below are key best practices to help organizations develop effective and impactful computer vision solutions:
Prioritize high-quality, diverse data
- Data is the foundation. The accuracy and robustness of models depend heavily on the quality and diversity of training data. Collect datasets that represent real-world variability – different lighting conditions, angles, occlusions, and object scales – to ensure models generalize well.
- Annotation accuracy matters. For classification, ensure consistent and correct image-level labels. For detection, bounding boxes must be tight, cover entire objects, and include occluded instances to avoid introducing false negatives or confusing the model.
- Leverage active learning. Combine human expertise with machine-assisted annotation to efficiently label large datasets, iteratively refining data quality and reducing manual effort.
Optimize data preprocessing and augmentation
- Normalize and resize images to maintain consistent input dimensions and pixel value ranges, improving model convergence.
- Apply augmentation techniques such as flipping, rotation, scaling, and color jittering to artificially expand dataset diversity and improve model robustness against real-world variations.
- Include challenging cases like occluded, blurred, or low-light images during training to enhance performance in complex environments.
Select and tune the right model architecture
- Match model complexity to project needs. For image classification, CNNs like ResNet or EfficientNet strike a balance between accuracy and efficiency. Vision Transformers (ViTs) can be considered for very large datasets requiring global context understanding.
- For object detection, choose between two-stage detectors like Faster R-CNN for high accuracy or single-stage models like YOLO and SSD for faster inference, especially important in real-time applications.
- Use transfer learning to leverage pre-trained weights, reducing training time and improving accuracy, especially when labeled data is limited.
Hyperparameter optimization and regularization
- Tune key hyperparameters such as learning rate, batch size, and optimizer choice to maximize model performance. Intelligent methods such as Bayesian optimization can efficiently explore hyperparameter space.
- Apply regularization techniques (dropout, L1/L2 penalties) to prevent overfitting and improve generalization on unseen data.
- Monitor training with appropriate metrics: accuracy, precision, recall, F1-score for classification; mean Average Precision (mAP) and Intersection over Union (IoU) for detection.
Balance accuracy and computational efficiency
- Optimize models for deployment environments. For edge or real-time applications, consider model pruning, quantization, and lightweight architectures to reduce latency without sacrificing critical accuracy.
- Leverage hardware acceleration with GPUs, TPUs, or specialized accelerators to speed up training and inference. Efficient memory management and parallel processing further boost performance.
- Continuously evaluate trade-offs between precision and speed to meet application-specific requirements.
Plan for scalable deployment and maintenance
- Choose deployment strategies aligned with business needs – on-premises for low latency and data privacy, cloud for scalability and flexibility, or edge computing for real-time processing close to data sources.
- Implement monitoring and feedback loops to track model performance post-deployment, enabling retraining and fine-tuning as data distributions evolve.
- Ensure integration compatibility with existing IT infrastructure for seamless operation and future scalability.
Summary table: Best practices for image classification and object detection implementation
| Aspect | Best Practices |
| Data quality | Diverse, well-annotated datasets; label occluded and partial objects; use active learning |
| Preprocessing & augmentation | Normalize, resize, augment with rotation, flipping, scaling; include challenging cases |
| Model selection | CNNs (ResNet, EfficientNet) for classification; Faster R-CNN, YOLO, SSD for detection |
| Training optimization | Hyperparameter tuning (learning rate, batch size); regularization (dropout, L1/L2); transfer learning |
| Performance balance | Optimize for accuracy vs speed; use pruning, quantization; leverage hardware acceleration |
| Deployment strategy | On-premises, cloud, or edge based on latency, privacy, and scalability needs |
| Maintenance | Continuous monitoring, feedback loops, retraining, and infrastructure integration |
FAQ about Image Classification vs Object Detection
1. What is the main difference between image classification and object detection?
Image classification assigns a single label to an entire image, identifying the dominant object or scene, while object detection identifies multiple objects in an image and locates them with bounding boxes.
2. When should I use image classification instead of object detection?
Use image classification when you only need to know what is in the image without requiring the location of objects, such as tagging photos or medical diagnosis.
3. Why is object detection more complex than image classification?
Object detection combines classification with localization, requiring models to both recognize and precisely locate multiple objects, which demands more detailed annotations and higher computational resources.
Partner with Experienced Providers
Consider working with experienced providers who can guide your team through the implementation process and help avoid common pitfalls. The complexity of image annotation projects makes professional support valuable for most organizations.
LTS GDS stands as a premier provider of high-precision semantic segmentation services. Our unwavering commitment to exceptional accuracy (consistently 98-99%), validated by rigorous multi-stage review processes and DEKRA certification, ensures that your machine learning models are built on a foundation of superior data. We possess deep expertise in handling complex semantic segmentation projects across diverse and demanding industries, including automotive, retail analytics, and industrial safety.
For businesses seeking professional support for their computer vision initiatives, our teams at LTS GDS offer comprehensive services from initial consultation through full scale implementation.
Learn more about our image annotation services and discover how we can support your semantic segmentation projects!



