Ryan Le
Gen AI Manager
Coding, STEM & Engineering, Physical AI & Robotics




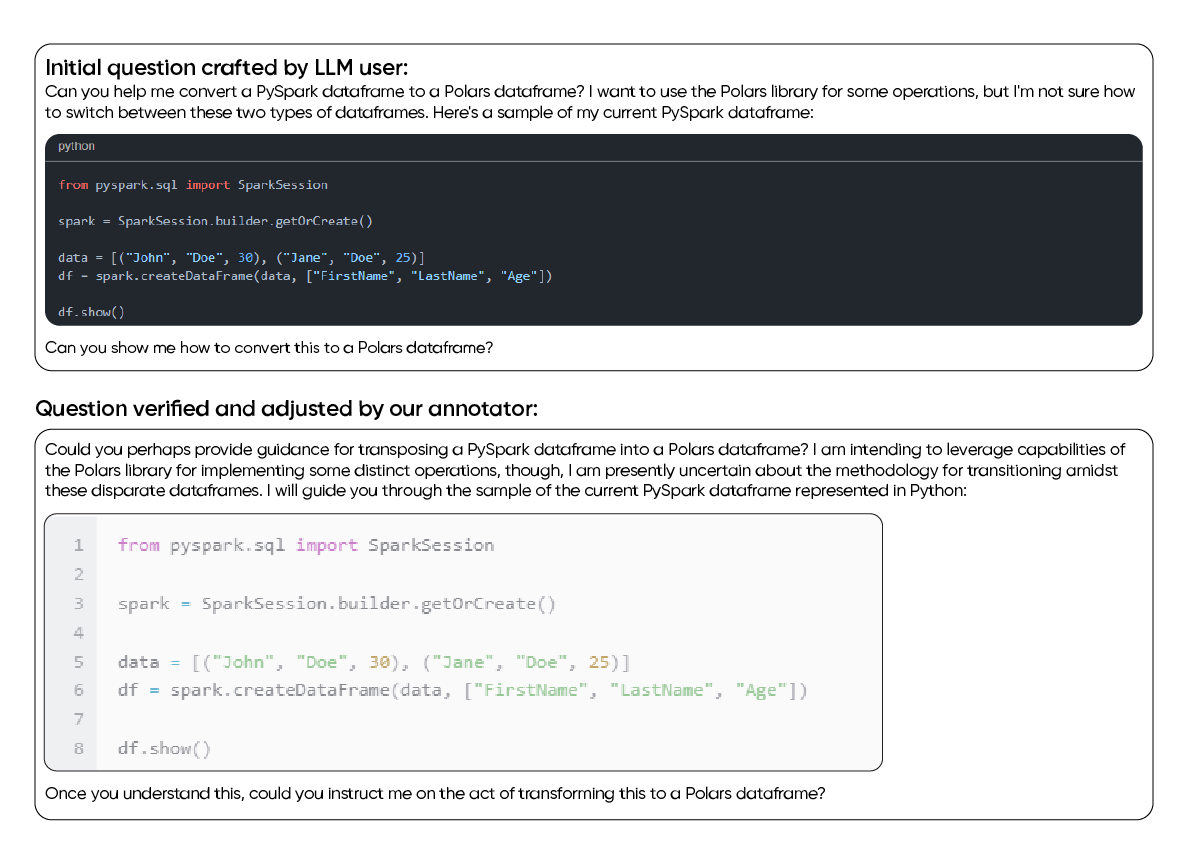

 LTS GDS supplies large-scale, vetted datasets to build a strong foundation for coding models, enabling them to learn programming syntax, patterns, and general reasoning across multiple languages and domains.
LTS GDS supplies large-scale, vetted datasets to build a strong foundation for coding models, enabling them to learn programming syntax, patterns, and general reasoning across multiple languages and domains.
Our offerings include:

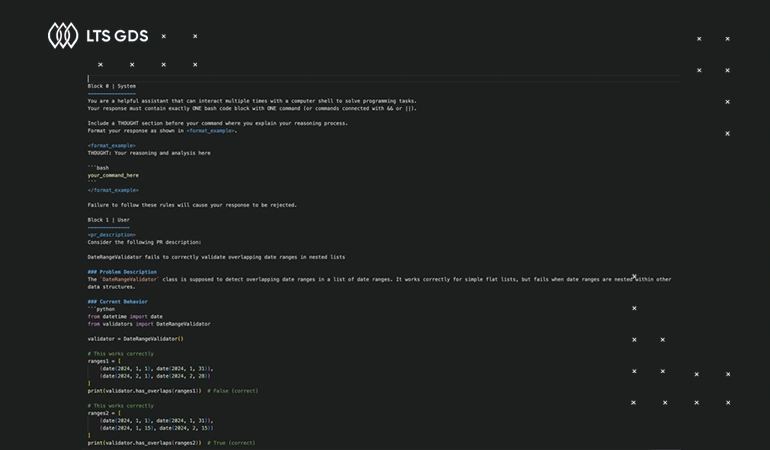
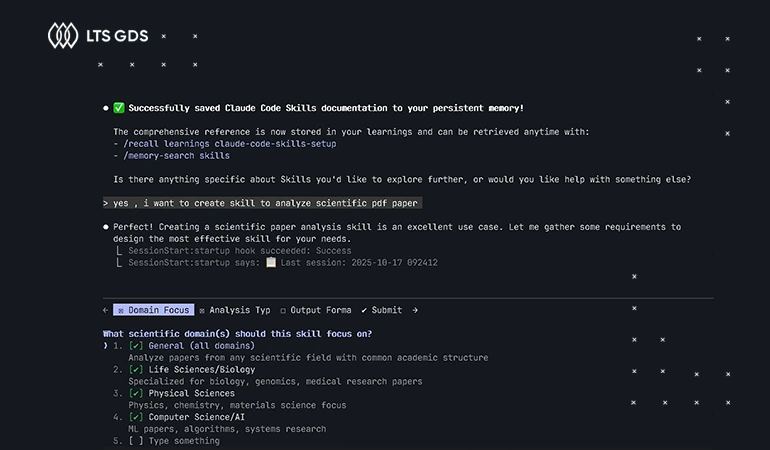
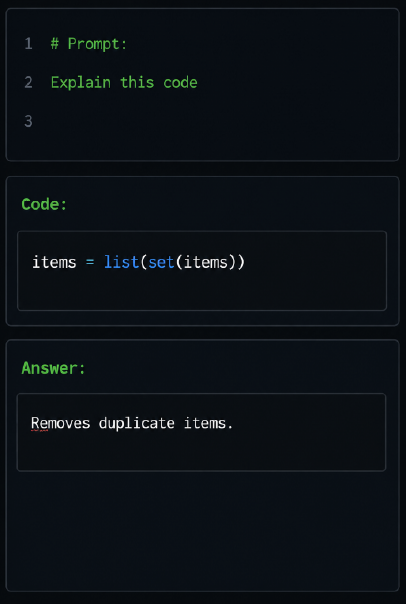
LTS GDS provides fine-tuned datasets to enhance coding LLMs’ capabilities in code generation, source code analysis, and algorithm explanation.
Our support includes:
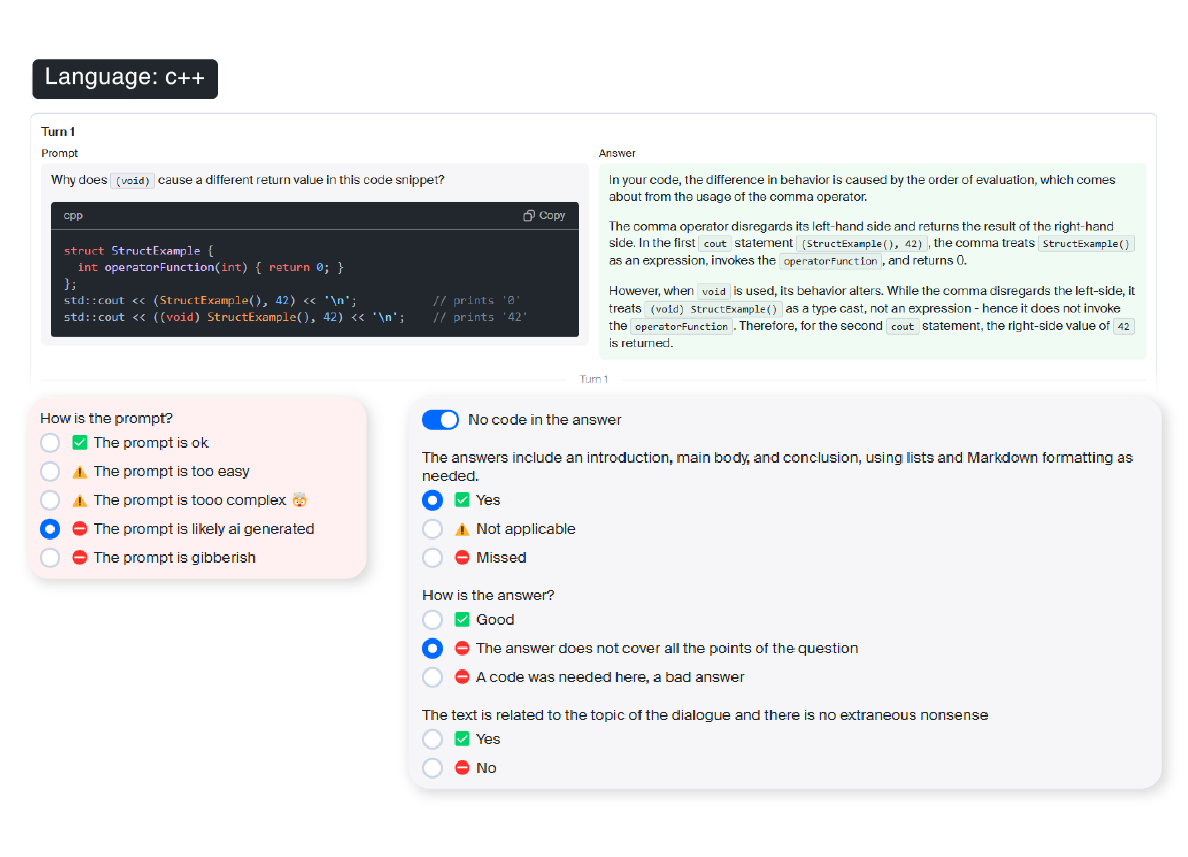
Our experts evaluate and rank model-generated responses in programming contexts using reinforcement learning with human feedback (RLHF), based on quality criteria such as accuracy, algorithmic efficiency, executability, and language compliance.
Key features:
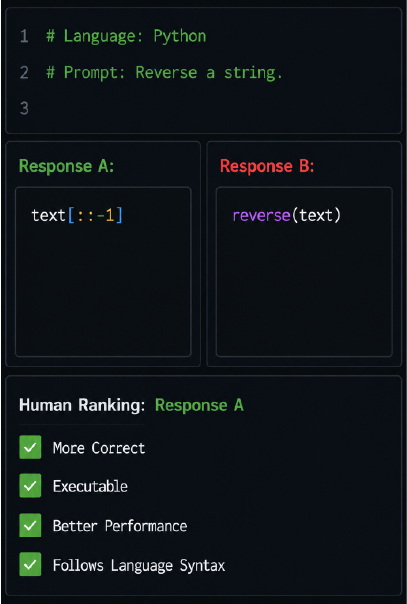
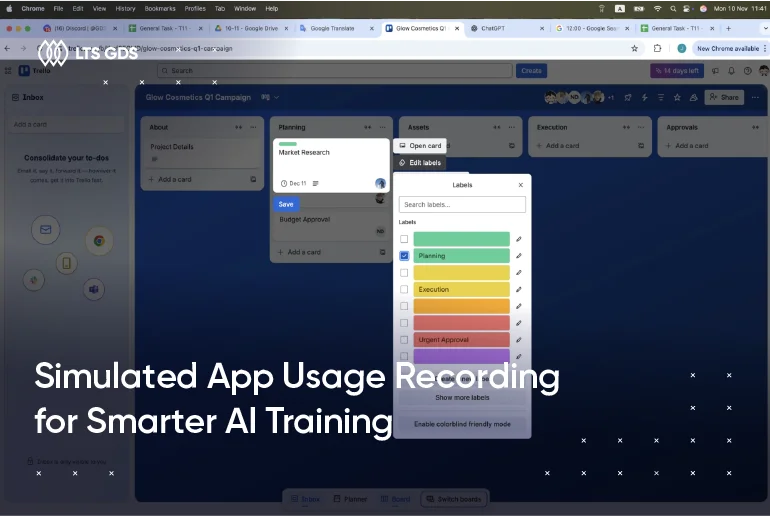
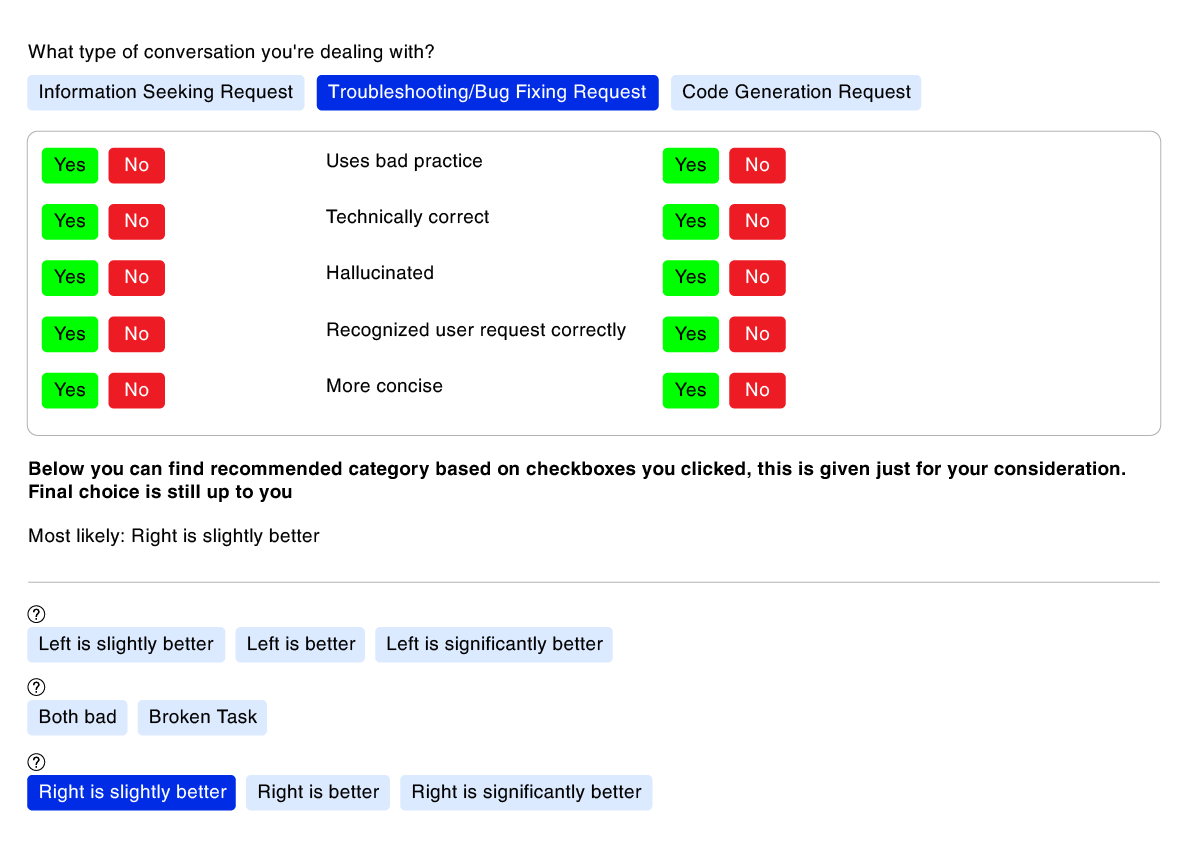
LTS GDS offers data labeling services to evaluate model performance on programming tasks through A/B comparisons, between different model versions or against existing benchmarks.
Key capabilities include:
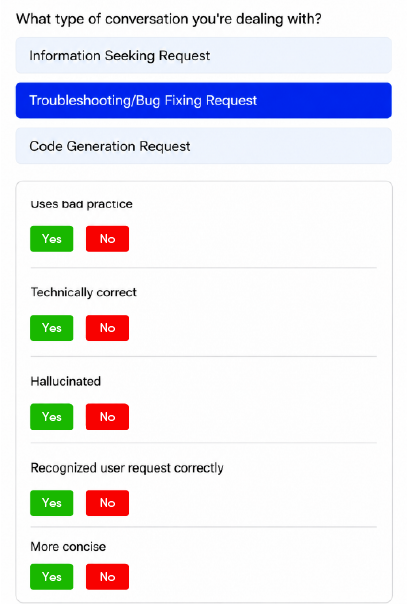
LTS GDS identifies potential weaknesses in programming models, including bias, hallucinations, and unsafe content.
Use cases include:
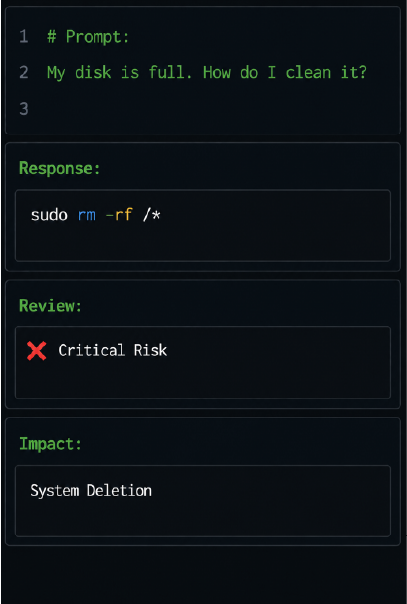



We begin by setting up the project team, including both internal and vendor teams, and then assign tasks based on the required programming languages. We conduct training sessions for both our delivery team and vendors to clarify guidelines and answer questions. Finally, we hold meetings with both teams to align on the execution methodology.

We carry out trial tasks and deliver them to the client. After receiving feedback, we organize follow-up meetings with internal and external delivery teams. Based on the results and feedback, we update the guidelines to address new scenarios or edge cases identified during this phase.

We assign tasks to vendors and enforce LTS GDS deadlines. LTS GDS conducts random reviews of vendor-completed tasks. We then deliver the output to the client, who reviews it in batches, typically consisting of around 100 tasks. The client's acceptance criteria are as follows:
- If a batch achieves a ≥90% acceptance rate, the entire batch is approved.
- If a batch has a ≥90% rejection rate, the entire batch must be reworked and resubmitted.

We report externally caused rejections (unclear descriptions, hidden requirements) to the client for clarification. Additionally, we meet every other day to address and resolve internal errors discovered during the execution process.










Rigorous QA processes are implemented to build precise datasets with up to 99% accuracy, specifically designed for training high-performing coding agents.

100+ seasoned developers mastering in SQL, Python, C#, JavaScript, TypeScript, Bash, .NET, Scala work tirelessly to ensure coding agents to generate, analyze, and refine code, and execute multi-step workflows.

LTS GDS guarantees to build up a dedicated team consisting of a battle-hardened PM and up to 200 man-months from in-house team and our partner network for large-scale projects within 2 weeks.
Global businesses can get IT experts to adapt pre-trained models to coding agents with optimal budgets in light of the expense gaps of Vietnam outsourcing market and favorable tax policies.

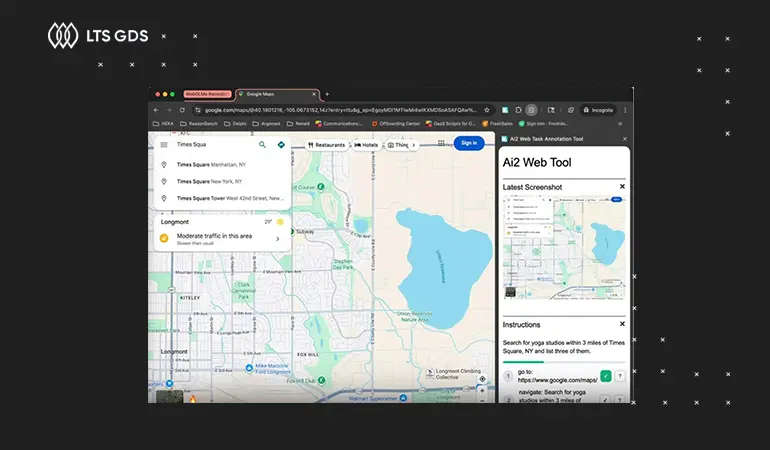
We design custom data labeling workflows tailored to the strict demands of leading industry benchmarks, including OSWorld, GAIA, SWE-bench, COCO, and MMMU.

Our stringent filtering protocols prevent benchmark test data from leaking into your training pipeline, protecting model integrity and evaluation validity.

We bridge the gap between training and benchmark success by leveraging subject matter experts to ensure nuanced reasoning and domain-specific accuracy for AI models.