



Imagine a self-driving car smoothly navigating busy city streets, anticipating pedestrian crossings, and responding flawlessly to traffic signals – all without a human behind the wheel. This seamless intelligence is powered by computer vision models meticulously trained on richly annotated video data.
Video annotation, the detailed process of labeling objects, actions, and events frame-by-frame, transforms raw video footage into structured datasets. Unlike static image labeling, video annotation captures both spatial and temporal information, enabling AI to understand not just what objects are present, but how they move and interact over time.
The outlook?
According to Grand View Research, the global data collection and labeling market, which encompasses video annotation, is projected to expand at an impressive compound annual growth rate of nearly 29% between 2023 and 2030, reaching a valuation of 17 billion USD.
For an in-depth overview of annotation types, methodologies, and practical implementation across industries, see our guide on what is data annotation: types, techniques & best practices.
In this blog, we will delve into the core principles of video annotation, explore the key techniques and challenges involved, and explain why this technology has become indispensable for powering the most advanced AI systems today.
What is Video Annotation?
Understanding video annotation fundamentals
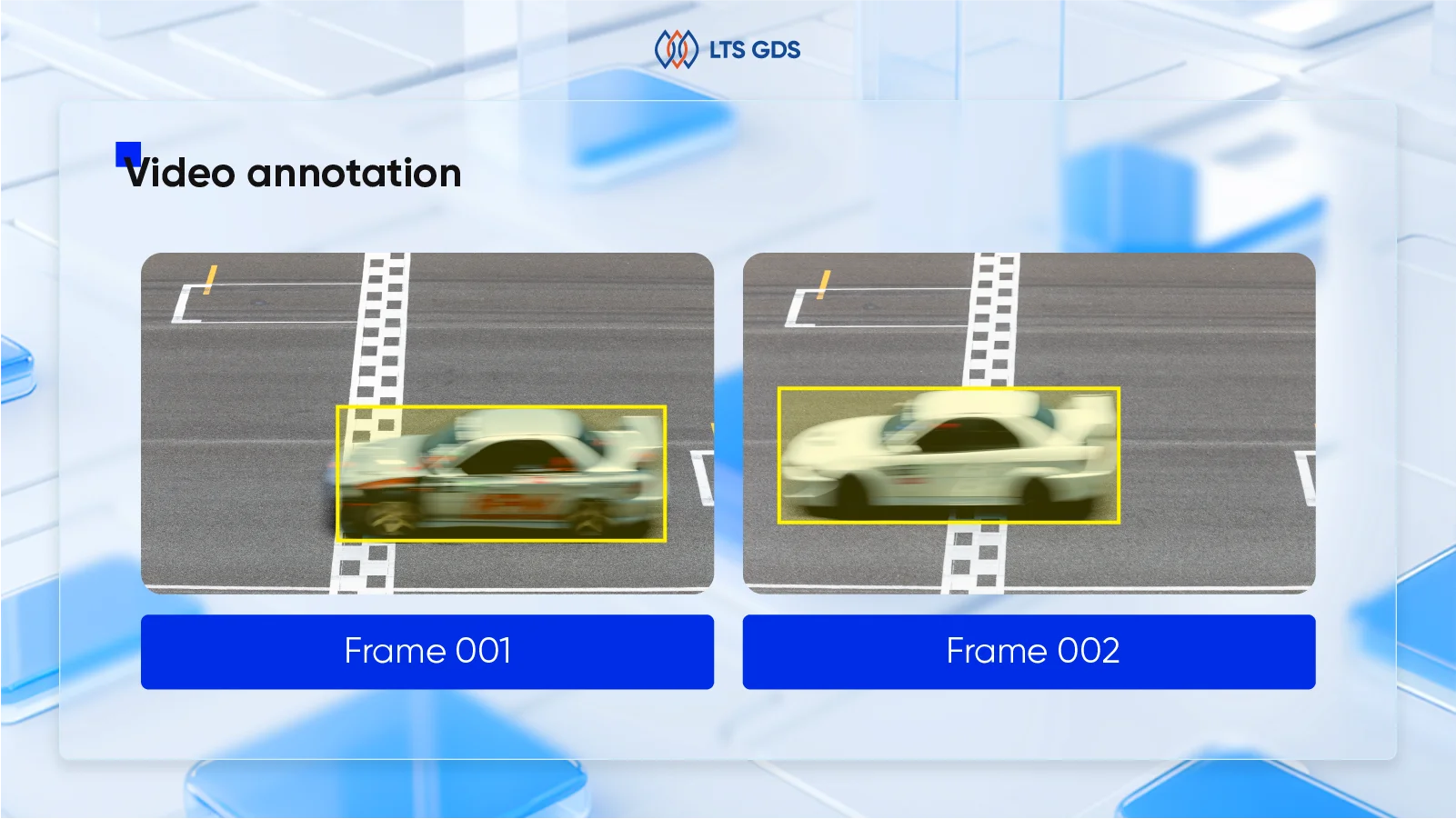
Video annotation is the process of labeling moving images frame-by-frame so that ML models can detect, classify, and track objects or actions over time. Unlike static image annotation, video annotation introduces a temporal component. This means not only tracking what something is but also where it goes and how it behaves across multiple frames.
For industries such as automotive, healthcare, surveillance, retail, and robotics, annotated video data is essential to train systems that can recognize pedestrian behavior, monitor patient movement, detect security threats, analyze customer journey flows, or guide autonomous machines.
Read our article on how data annotation transforms automotive AI.
Video annotation vs image annotation
Image annotation involves labeling objects in single, static images. Each image is treated independently, making it simpler and faster. It’s great for tasks like product tagging, medical scans, or satellite photos.
Video annotation is more complex because it labels objects across many frames in a video. This means tracking movement, changes, and interactions over time. It’s essential for applications like self-driving cars, security cameras, and sports analysis.
| Feature | Image annotation | Video annotation |
| Data type | Single images | Sequence of frames (video) |
| Time factor | No | Yes, captures motion and changes over time |
| Complexity | Simple | More complex, requires tracking objects |
| Tools Needed | Basic annotation tools | Advanced tools with tracking and interpolation |
| Use Cases | Static object detection | Movement and behavior analysis |
In short
Use image annotation for static scenes, and video annotation when understanding motion and context is important.
Types of video annotation techniques
Annotations can take various forms, including:
- Bounding boxes: Rectangular frames around objects.
- Polygons: precise outlines for irregular shapes.
- Keypoints: Specific points marking object features (e.g., human joints).
- Semantic segmentation: Pixel-level classification of objects.
- Instance segmentation: Differentiating multiple instances of the same object class.
Such detailed labeling empowers AI models to perform tasks like object detection, tracking, pose estimation, and action recognition with remarkable accuracy.
Bounding boxes

Bounding boxes are the most widely used annotation technique. They involve drawing rectangular boxes around objects of interest. This method is efficient and effective for object detection tasks, such as identifying vehicles, pedestrians, or animals in a scene.
Polygons

For more precise object delineation, polygons trace the exact shape of an object, excluding background pixels. This method is critical when shape details affect AI performance, such as in medical imaging or industrial inspection.
Keypoints/ Landmarks

Keypoint annotation marks specific points on an object, such as human joints or facial landmarks. When connected, these points form skeletons that allow AI to analyze posture, gestures, and movement patterns – vital for applications in sports analytics, physical therapy, and human-computer interaction.
Semantic and instance segmentation

Semantic segmentation assigns a class label to every pixel in a frame, categorizing regions like roads, buildings, or vegetation. Instance segmentation goes further by distinguishing individual objects within the same class, enabling AI to differentiate between multiple pedestrians or vehicles.
For a deeper understanding of segmentation techniques, explore LTS GDS’s resources on types of image segmentation
Temporal segmentation extends the principles of semantic segmentation and instance segmentation into the time domain. This technique proves invaluable for applications requiring precise boundary definitions that change over time, such as medical imaging where organ boundaries shift with patient movement or breathing.
Understanding the difference between semantic segmentation vs instance segmentation becomes crucial when applying these concepts to video data, where temporal consistency adds another layer of complexity.
Cuboids and 3D annotations

Cuboids extend bounding boxes into three dimensions, providing spatial context crucial for autonomous vehicles and robotics, where understanding depth and volume is necessary for navigation and manipulation.
Why Video Annotation Matters and Industry Applications
In the AI lifecycle, data is king. The quality of training data directly influences model performance. Video annotation serves as the bridge between raw video data and intelligent machine learning models.
By meticulously labeling objects, actions, and events across sequences of frames, video annotation provides the structured data that powers advanced computer vision and machine learning systems.
The importance of video annotation in AI
- Teaching machines to see and understand: Annotated videos serve as foundational training data, allowing AI to recognize objects, track movements, and interpret complex scenarios – capabilities that static images alone cannot provide.
- Unlocking temporal intelligence: Video annotation captures not only what is present in each frame, but also how objects move and interact over time, making it indispensable for tasks that require understanding of motion, behavior, and context.
- Enabling real-world AI deployment: From self-driving cars to medical diagnostics, annotated video data bridges the gap between laboratory models and practical, real-world AI solutions.
In-depth: Applications of video annotation across industries
| Industry | Application areas | Example outcomes |
| Autonomous vehicles | Object/lane detection, behavior prediction | Safer navigation, accident prevention |
| Security | Threat detection, event tagging | Faster incident response, cost savings |
| Healthcare | Surgical assistance, anomaly detection | Improved diagnostics, patient safety |
| Retail | Customer tracking, layout optimization | Higher sales, better customer service |
| Sports | Player tracking, performance analysis | Enhanced coaching, injury prevention |
| Manufacturing | Quality control, anomaly detection | Reduced downtime, higher productivity |
| Agriculture | Crop/livestock monitoring, yield analysis | Increased efficiency, higher yields |
Autonomous vehicles
Self-driving cars depend on annotated video data to safely navigate roads, detect pedestrians, recognize traffic signals, and anticipate the actions of other vehicles. Video annotation enables these systems to interpret complex, dynamic environments, ensuring real-time decision-making and accident prevention.
- Key tasks: Object detection (cars, pedestrians, cyclists), lane and traffic sign recognition, behavior prediction.
- Impact: Waymo, for example, has annotated over 100 years’ worth of driving footage to train its autonomous systems.
Security and surveillance
AI-powered surveillance systems use annotated videos to identify suspicious behaviors, track individuals, and detect anomalies in real time. Video annotation allows for efficient searching and filtering of footage, enhancing security in public spaces, retail stores, and critical infrastructure.
- Key tasks: Motion detection, facial recognition, event tagging, threat identification.
- Impact: Retailers have saved significant costs by using AI video analytics to reduce shoplifting and improve incident response.
Healthcare and medical diagnostics
In healthcare, annotated videos are used to train AI for surgical assistance, patient monitoring, and early disease detection. By labeling anatomical structures, medical instruments, and physiological events, video annotation enhances diagnostic accuracy and operational efficiency.
- Key tasks: Tracking surgical tools, identifying anatomical landmarks, detecting anomalies in endoscopy or ultrasound videos.
- Impact: AI analysis of annotated echocardiogram videos has improved heart failure prediction by 37% in some studies.
Retail and customer experience
Retailers leverage video annotation to analyze shopper behavior, optimize store layouts, and personalize marketing strategies. By tracking customer movement and interactions, businesses gain actionable insights to enhance sales and service.
- Key tasks: Customer traffic analysis, product interaction tracking, queue management.
- Impact: AI-powered video analytics have reduced checkout wait times by up to 41% in some grocery chains.
Sports analytics
In sports, annotated video data helps coaches and analysts break down player movements, strategies, and performance metrics. This enables precise feedback, injury prevention, and tactical optimization.
- Key tasks: Player tracking, action recognition, event tagging.
- Impact: The NBA’s partnership with AI analytics firms has increased 61% data capture and performance insights, transforming coaching and player development.
Manufacturing and industrial automation
Manufacturers use video annotation to monitor production lines, detect defects, and automate quality control. Annotated videos enable AI systems to spot anomalies, predict maintenance needs, and optimize workflows.
- Key tasks: Visual inspection, anomaly detection, equipment monitoring.
- Impact: Plants using AI video monitoring have significantly reduced downtime and operational costs.
Agriculture and environmental monitoring
In agriculture, annotated drone and satellite videos help monitor crop health, detect pests, and manage livestock. These insights drive precision farming and increase yields.
- Key tasks: Crop disease detection, livestock tracking, yield estimation.
- Impact: Farms using AI crop analytics based on annotated video have improved annual profits by over 10%.
The Video Annotation Process
Video annotation is a multi-step, iterative process that requires a blend of human expertise and technological innovation.

Step 1: Define objectives and annotation schema
Before annotation begins, it’s crucial to understand the AI model’s goals. What objects or actions need labeling? What level of granularity is required? This step involves designing an annotation schema that aligns with the client’s use case.
Step 2: Data preparation and segmentation
Videos are uploaded and segmented into manageable clips or frames. The choice of frame rate and resolution impacts annotation detail and processing time.
Step 3: Annotation execution
Annotators label keyframes, selected frames where objects are manually annotated. Between these keyframes, interpolation algorithms predict object positions, significantly reducing manual effort. Annotation tools support various techniques such as bounding boxes, polygons, and keypoints.
Step 4: Quality assurance
Quality control is paramount. Multiple rounds of review ensure annotations are consistent, accurate, and meet project specifications. Automated validation scripts may also detect anomalies or inconsistencies.
Step 5: Data delivery and integration
Annotated videos are packaged in formats compatible with AI training pipelines. Integration with software development workflows ensures seamless deployment into model training and testing.
Technical Challenges in Video Annotation
Video annotation presents unique obstacles that demand technical foresight and operational agility. Key challenges include:

Data volume & frame density
Videos consist of thousands of frames. Manually annotating long sequences is time-consuming, resource-intensive, and prone to human error. Processing speed and cost efficiency must be balanced without compromising accuracy.
Motion blur and occlusion
Fast-moving subjects or those partially hidden (e.g., a pedestrian behind a car) can result in ambiguous annotations. This impairs training data quality and complicates model generalization.
Annotation drift
Over long sequences, bounding boxes or keypoints may drift due to frame-to-frame discrepancies. This cumulative error, if unchecked, can skew the dataset significantly.
Temporal consistency
Annotators must maintain object identity and label consistency across frames. Failure to do so reduces tracking accuracy and impairs model training for tasks like object re-identification or action recognition.
Visual fatigue & workforce turnover
High-volume video annotation leads to annotator fatigue, decreasing precision. Maintaining a motivated, trained workforce, especially in long-term projects, is a logistical and managerial challenge.
Tool limitations
Not all annotation platforms handle temporal data equally well. Frame lags, lack of interpolation, or limited collaborative features can reduce throughput and data quality.
Best Practices for Video Annotation Excellence
Effective video annotation requires clear objectives, consistent execution, and rigorous quality control. The following best practices provide practical guidance to ensure your annotation efforts deliver accurate, reliable data for AI success.
 1. Leverage interpolation & automation
1. Leverage interpolation & automation
Don’t annotate every frame manually. Smart interpolation algorithms can auto-propagate labels across frames, drastically speeding up workflows.
2. Establish clear annotation guidelines
Consistency is key. Develop detailed documentation covering object classes, occlusion handling, motion ambiguity, and edge cases to ensure all annotators are aligned.
3. Use hierarchical review workflows
Introduce multiple review layers, peer review, lead QA, and model-assisted validation, to detect and correct issues early.
4. Prioritize temporal continuity
Emphasize object persistence across frames. Use consistent IDs and smooth transitions to support accurate object tracking.
5. Split long videos
Break lengthy videos into manageable segments. This reduces annotator fatigue and allows for parallel processing without sacrificing quality.
6. Perform regular QA audits
Periodically sample completed annotations for quality review. Use both random sampling and targeted review of complex or high-risk sections.
7. Maintain annotator training & calibration
Continuously train and calibrate annotators using feedback loops, sample tasks, and updated guidelines.
8. Integrate feedback from model performance
Use model outputs to identify misannotations or underperforming patterns then iterate on annotation strategy accordingly.
FAQ about Video Annotation
1. What is video annotation?
Video annotation is the process of adding labels, tags, or metadata, such as bounding boxes or keypoints, to video frames, enabling AI models to recognize and track objects or actions over time.
2. How do you ensure quality in video annotation?
Quality is maintained through clear guidelines, consistent labeling, regular reviews, and by combining automated tools with expert human oversight
3. What tools and services are best for video annotation?
Top annotation tools like Labellerr, Labelbox, and SuperAnnotate offer advanced features such as bounding boxes, polygons, and AI-assisted auto-labeling to speed up and improve accuracy.
For end-to-end solutions, service providers like LTS GDS combine expert human annotators with powerful software to deliver high-quality, scalable video annotation tailored for industries like autonomous vehicles, healthcare, and retail.
4. What trends will define video annotation going forward?
The future includes deeper AI integration, 3D and synthetic video annotation, cloud-based collaboration, and advanced quality control that will enable industries such as healthcare, autonomous driving, and security access high-quality annotated data at scale.
Partner with Experienced Providers
Consider working with experienced providers who can guide your team through the implementation process and help avoid common pitfalls. The complexity of video annotation projects makes professional support valuable for most organizations.
LTS GDS stands as a premier provider of high-precision video annotation services. Our unwavering commitment to exceptional accuracy (consistently 98-99%), validated by rigorous multi-stage review processes and DEKRA certification, ensures that your machine learning models are built on a foundation of superior data. We possess deep expertise in handling complex video annotation projects across diverse and demanding industries, including automotive, retail analytics, and industrial safety.
For businesses seeking professional support for their computer vision initiatives, our teams at LTS GDS offer comprehensive services from initial consultation through full scale implementation.
Learn more about our data annotation services and discover how we can support your semantic segmentation projects!


