Ryan Le
Gen AI Manager
Coding, STEM & Engineering, Physical AI & Robotics




 LTS GDS는 코딩, 고객 지원, 의료, 금융 등 다양한 활용 사례와 전문 분야에서 LLM 역량을 강화하기 위해 정교하게 조정된 데이터셋을 제공합니다.
LTS GDS는 코딩, 고객 지원, 의료, 금융 등 다양한 활용 사례와 전문 분야에서 LLM 역량을 강화하기 위해 정교하게 조정된 데이터셋을 제공합니다.
주요 작업:

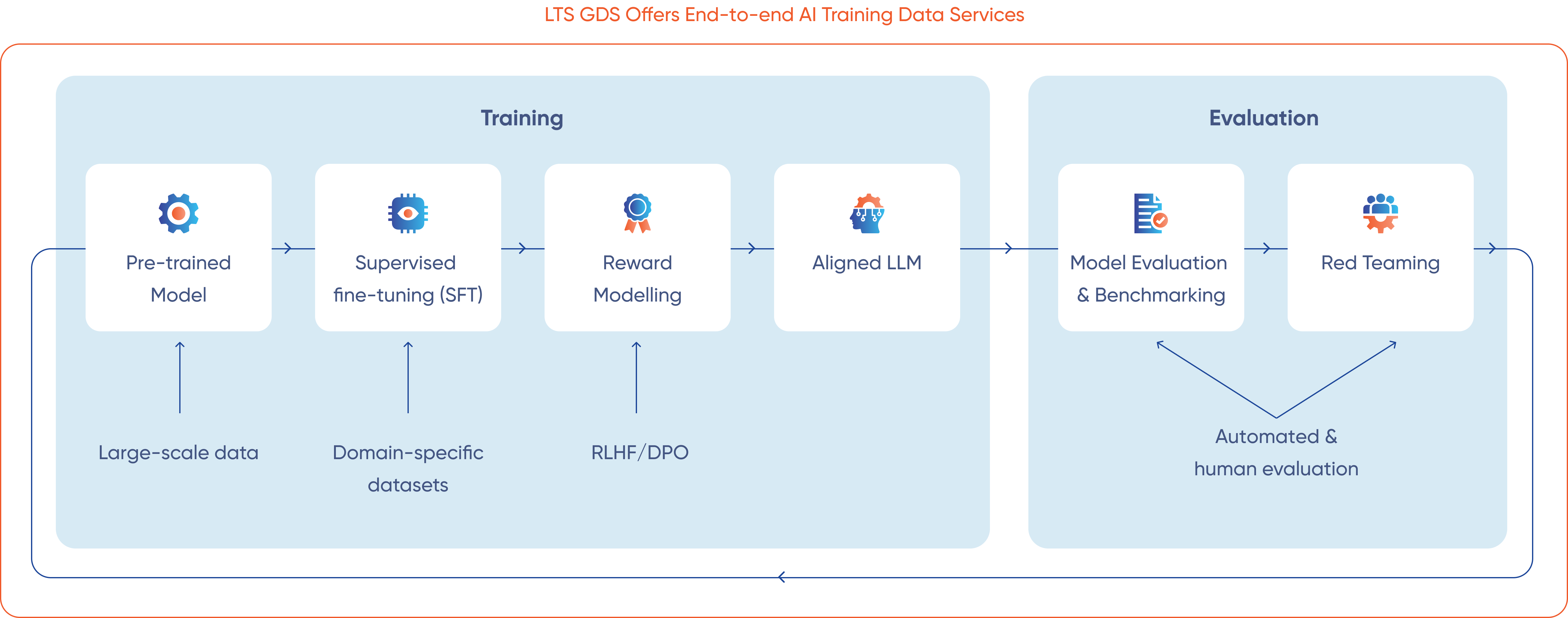
전문가들은 RLHF(인간 피드백을 통한 강화 학습)과 DPO(직접 선호 최적화) 기법을 적용하여 모델이 생성한 응답을 다양한 맥락에서 체계적으로 검증합니다. 평가 기준에는 논리적 타당성, 정확성, 의미적 일관성, 윤리적 준수 등이 포함됩니다.
핵심 기능:

LTS GDS는 구조화된 평가 서비스를 제공하여 LLM 성능을 A/B 테스트 방식으로 검증하고, 모델 버전 간 비교 및 업계 벤치마크와의 대조를 수행합니다.
핵심 기능:

LTS GDS는 LLM의 안전하고 신뢰할 수 있는 배포를 위해 잠재적 약점을 체계적으로 식별합니다. 레드팀 절차는 편향, 환각, 안전하지 않은 출력 등 다양한 취약성을 검출합니다.
포함하는 활용 사례:


Vietnamese

English

Russian

Mandarin Chinese

Cantonese

Japanese

Korean

Malay

Indonesian

Thai

Lao

Hindi

Arabic

French

German

Spanish

Portuguese

Italian

Bulgarian

Hungarian
Engineering
Civil Engineering
Law
Finance
Accounting
Economics
Mathematics
Computer Science
Medicine
Psychology
Physics
Healthcare
Chemistry
Biology
Astronomy
Biotechnology
Bioinformatics
Teaching
Linguistics
Religion
Language Arts
Music
Philosophy
History
Performing Arts
Robotics Engineers
Computer Scientists
Software Engineers
Systems Architects
Data Engineers
AI/ML Researchers
Financial Analysts
Accountants
Auditors
Economists
Investment Bankers
Risk Managers
Psychologists
Sociologists
Political Scientists
Administrators
Scientists
Mathematicians
Photographers
Screenwriters
VFX Supervisors
Cinematographers
Art Directors
Creative Directors
Animation Directors
3D Modelers
Sound Designers
Audio Engineers
Music Composers
Voice Directors


전담 프로젝트 관리자가 고객과 긴밀히 협력하여 비즈니스 목표, 데이터 소스, LLM 학습 필요성을 파악합니다. 모델 범위, 도메인 요구, 학습 방법, 규정 준수, 기대 결과, 비용 요소를 평가한 후 맞춤형 LLM 학습 전략을 제안합니다.

LTS GDS는 필요 시 전 세계 다양한 지역의 벤더 파트너와 내부 전문가로 구성된 전담 딜리버리 팀을 조직합니다. 모든 팀원이 프로젝트 목표, 데이터 주석 및 준비 표준, 실행 방법론을 이해하도록 교육합니다.

확장 전에 시험 작업을 수행하여 프로세스를 검증합니다. 산출물을 고객에게 공유하고 피드백을 반영하여 지침을 업데이트합니다. 이 단계는 특수 사례를 정제하고 일관성을 개선하며 LLM 학습 프로세스가 비즈니스 목표와 일치하도록 합니다.

LTS GDS는 엄격한 일정과 정기적인 품질 검사를 통해 대규모 LLM 학습 및 파인튜닝을 관리합니다. 전문 팀이 각 작업을 처리하며, 지속적인 회의를 통해 고객 피드백에 맞게 프로세스를 조정합니다. 고객과 함께 명확한 평가 기준을 정의하여 산출물 품질을 측정하고 결과를 기대 수준까지 개선합니다.

요구 사항 불명확성이나 숨은 시나리오를 고객에게 적극적으로 보고합니다. 내부 팀은 정기적으로 회의를 열어 오류를 해결하고 워크플로우를 업데이트하며 LLM 학습 결과를 장기적으로 강화합니다.










저희는 높은 정확도로 신뢰할 수 있는 LLM 학습 결과를 제공합니다. 다층 검토 과정을 통해 모델을 비판적 사고와 문맥 이해로 정교하게 다듬습니다.

AI 트레이너들은 다양한 산업에 대한 깊은 지식을 바탕으로 전문 용어를 이해하고 실제 요구를 충족하는 도메인 특화 LLM을 구축합니다.

다양한 지역 시장과 문화권에 걸친 대규모 팀을 통해 전문가들은 다국어 활용 사례와 문화적 뉘앙스에 자연스럽게 적응하는 LLM을 훈련합니다.
베트남의 경쟁력 있는 인건비, 우호적인 비즈니스 환경, 유연한 가격 모델을 활용하여 LLM 프로젝트를 최적화합니다.