




What is data annotation?
The process of tagging data (photos, videos, text, audio) is data annotation, which helps machine learning models recognize and understand what they are, and then use them to generate predictions in the future
Why do we need to have data annotation?
Annotated data is essential for supervised machine learning because, in practice, ML models need to have large volumes of annotated data for object detection and decision-making processes. This is a reason why the quality of annotated data will be one of the key factors to ensure the decision is accurate and relevant.
Common data types
There are various data types including photo, video, text, audio, and 3D sensor data.
Photo
This is an image of people, objects, animals… This data has a high number in many projects. Some industries such as self-driving cars or automated medical devices require numerous numbers of image annotations. With efficient and precise annotation, AI systems may learn from trained photos to operate flawlessly without human interaction.
Video
It is a tape recording from a CCTV or camera, typically broken up into scenes. Compared to images, video is a sequence of consecutive images, each image will have only a slight change from the previous one, requiring the annotator to handle it carefully and accurately to show the continuity of the motion in the video frames.
Text
It is a document or word, number in numerous languages. By adding labels for words, phrases, and sentences, machine learning can understand the content, as well as identify the content that it’s targeting, such as People’s name, Country name, … or even emotions and attitudes, which is widely applied for natural language processing (NLP).
Audio
They are audio recordings made by individuals with different demographics. Any audio recording that has been made as sound can have additional keynotes and relevant information added to it. Audio can also be any kind of noise and sound, like cries, screams, and gunshots, … they’ve been studied and applied a lot in the field of voice AI.
3D sensor data
It is a 3D model generated by sensor devices. The type of data collected from 3D sensors is often more complex than the data from a conventional camera. 3D sensors can operate even in the dark as they use infrared light sources. Besides, 3D sensors can estimate object sizes more accurately than cameras.
Types of data annotation
There are many different types of data annotation in various projects, the type of annotation depends on what objects need to be detected, and the needs of the customers. To define the kinds of data annotation, we base data types and data annotation tools.
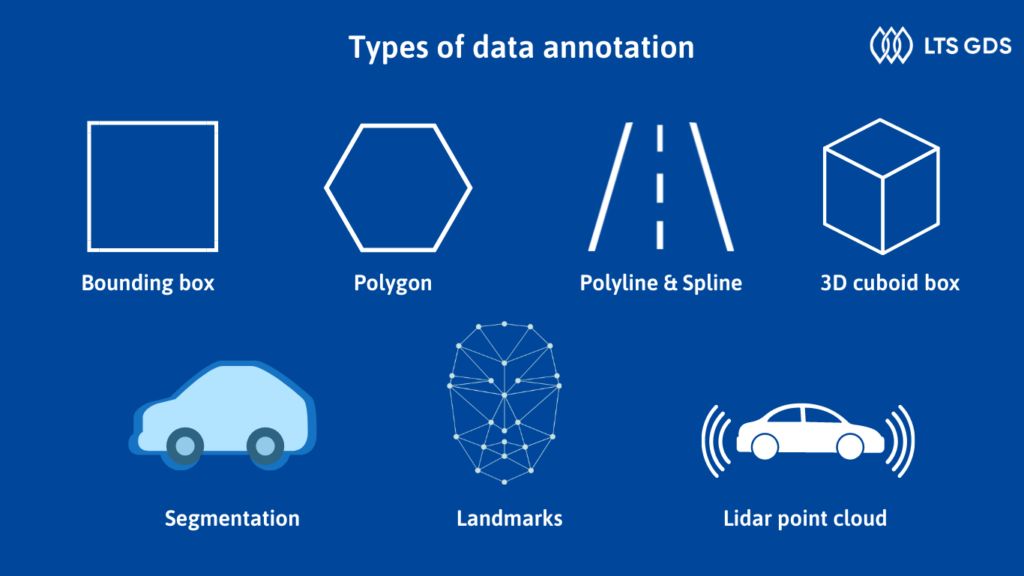
Bounding box
The annotators use a bounding box to draw a rectangle around an object. The bounding box needs to surround the outermost point of the annotated objects. It is used in detecting objects and classifying the position of objects such as cars, or people. This type is the simplest way and is quick to carry out.
Polygon
If you want a more precise result for irregular objects like human bodies, logos, or street signs, you should use polygons. The boundaries that are drawn around the objects can provide a precise picture of their shape and size, enabling the machine to anticipate outcomes more accurately.
Polyline & Spline
Polyline and spline are created by using small lines, connected at vertices. Annotators apply them to define linear structures in images and videos like roads, rail tracks, and pipelines. For example, polyline & spline annotation allow machine learning models for automated vehicles to detect lanes and identify the right lanes during the journey.
3D cuboid box
The cube that surrounds an object in a 2D image, determines the depth of the targeted object. 3D cuboids are most often used in self-driving car technology, which can help to measure the distance to obstacles and calculate the spacing.
Semantic segmentation
A task of associating a label or category with every pixel in an image, to recognize all the pixels belonging to the same classes. Using this method helps the machine learning algorithm classify specific features. For instance, semantic segmentation is used for industrial inspection to detect shortages or waste of materials.
Landmark
Landmark (KeyPoint) annotation is the process that localizes key point positions on the face, or body. This type of method is useful for detecting gestures and emotions on the face or motion tracking in sports. Annotators can only use landmark annotation or combine other types of data annotation to create a point map, which defines the poses of people.
LiDAR point cloud
A remote sensing technology that uses light in the form of laser pulses to measure distances between the sensor and target objects. The targeted objects in point cloud images can be annotated by bounding box, 3D cuboid, or others, depending on project requirements. LiDAR point cloud is applied in various industries, the most prominent are the applications for self-driving cars.
Popular tools for data annotation
In the data annotation process, some popular tools help annotators carry out the process more easily:
- Labellmg
- GIMP
- CVAT
- Label Studio
- V7
- LTS Annotation
- Super Annotate
- RectLabel
- Basic AI
- ViTBAT
3 steps in the data annotation process
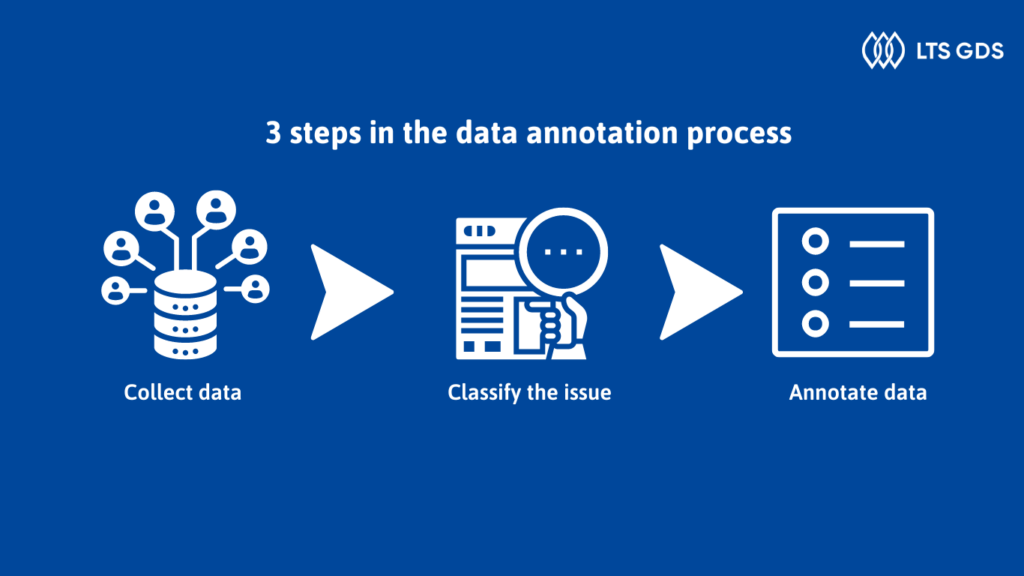
First step: Collect data
Data collection is the process of gathering, measuring, and analyzing information from many sources for specific purposes. There are many ways to collect data. We can research keywords on Google and save photos, and videos. Besides, we can buy data from external sources or find data from a public camera. In addition, we can collect data by taking images, recording audio or recording videos. To collect data, we identify types of data and the methods of collecting to meet the required information. Furthermore, we need to focus on the quality of resolution in various projects.
Second step: Classify the issue
Before choosing the techniques, you use with collected data, you identify the requirement of the problem like classifying images or detecting objects. Clearly identifying the problem of each project will help your team save time and budget.
Final step: Annotate data
After collecting data and identifying the problem, we carry out annotated data. Annotators use data annotation types (bounding box, 3D cuboid box, LiDAR point cloud…) to label data types. Data annotation processes can be done automatically with some automated tools or done manually, each way will have its advantages and disadvantages. For example, automatic data annotation is faster, while manual data annotation has higher accuracy with complex data.
Who are potential vendors?
Many factors affect the quality of data, one of which is choosing the right data annotation service provider. Companies can opt for online data annotation tools for the company or let their internal staff take charge. In addition, AI companies can choose outsourcing companies that specialize in providing data annotation services.
Read more: How to choose the best data annotation outsourcing company?
LTS GDS offers a high-quality and secure service for partners with a dedicated team. Contact us to get more information!


