



In 2025, 67% of enterprises worldwide have integrated Large Language Models (LLMs) into their operations, reflecting a decisive shift toward AI-driven transformation. However, according to Gartner, despite widespread adoption, only about 45% of organizations with high AI maturity sustain AI projects for three years or more, underscoring ongoing challenges in achieving domain-specific accuracy and adaptability essential for long-term success.
This discrepancy highlights that success in AI deployment hinges not on raw computational power but on how effectively organizations fine-tune these models for their unique business contexts.
Among the fine-tuning techniques, Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) stand out as pivotal methods for adapting Large Language Models (LLMs) to meet domain-specific demands.
SFT delivers reliable, high-precision outputs when trained on curated labeled data, making it ideal for well-defined tasks. RLHF, by incorporating iterative human feedback, enhances model alignment with complex, evolving user needs but often demands greater resources and may reduce output diversity.
In this article, we’ll dive into the comprehensive analysis of SFT vs RLHF, exploring their strengths, limitations, and strategic applications while offering insights as well as best practices to help enterprises strategically select and apply fine-tuning methods that optimize multimodal AI performance.
The Rise of Fine-Tuning in Large-Language Models
While generic LLMs provide broad language understanding, they often fall short when deployed directly in specialized enterprise contexts such as precise code generation, customer support automation, or healthcare text analysis. Fine-tuning is essential to bridge this gap, aligning models with human expectations and business goals by customizing their behavior on domain-specific datasets.
For organizations looking to understand the fundamental concepts behind model customization, our comprehensive guide on data labeling for fine-tuning LLMs provides essential insights into what fine-tuning entails and how fine-tuned models differ from their base counterparts.
The benefits of fine-tuning include:
- Deep integration of specialized knowledge: Fine-tuning “embeds” domain-specific information directly into the model’s weights, improving performance on targeted tasks.
- Customization of style and format: Models can be trained to produce outputs in specific formats or tones, such as generating JSON responses or adhering to regulatory language.
- Enhanced handling of complex generation tasks: Fine-tuning improves the model’s ability to follow multi-step instructions or generate creative, rule-based content.
As enterprises adopt multimodal AI combining language, vision, and other data types, fine-tuning remains key to delivering tailored, high-performance AI solutions that meet evolving business demands.
Supervised Fine-Tuning (SFT): Precision through Structured Learning
Supervised Fine-Tuning (SFT) is a structured learning process that adapts a pre-trained Large Language Model (LLM) to perform specific tasks by training it on a high-quality, labeled dataset containing input-output pairs. This process refines the model’s parameters to generate precise, context-aware responses aligned with the target application.
How SFT works

Step 1: Dataset preparation
- Data collection: Gather raw data relevant to the specific domain or task. The dataset size can vary from hundreds to tens of thousands of examples depending on complexity and model size.
- Data structuring: Format the data into structured pairs, typically in JSON Lines (JSONL) format, where each entry contains an input prompt and the corresponding desired output.
- Quality assurance: Ensure data accuracy, consistency, diversity, and minimize biases to avoid negatively impacting model behavior.
Step 2: Tokenization
- Convert text inputs and outputs into tokens (the model’s basic units of understanding) using a tokenizer compatible with the pre-trained model. This step enables efficient processing and learning.
Step 3: Fine-tuning training loop
- Next token prediction objective: SFT uses the same training objective as pre-training, predicting the next token in a sequence, but focuses only on the output portion of the input-output pairs.
- Forward pass: The model processes the input tokens and generates predicted tokens for the output sequence.
- Loss calculation: Compute the difference (loss) between the predicted tokens and the actual tokens from the labeled dataset.
- Backpropagation: Adjust the model’s weights to minimize this loss using gradient descent and optimization algorithms.
- Iteration: Repeat this process over multiple epochs, gradually improving the model’s task-specific performance.
Step 4: Evaluation and validation
- Use a separate validation dataset to monitor the model’s accuracy and prevent overfitting. Hyperparameters such as learning rate, batch size, and number of epochs are tuned based on validation results.
Step 5: Deployment
- Once the model achieves satisfactory accuracy and generalization, it is deployed for real-world applications such as chatbots, content generation, or domain-specific assistants.
SFT training process summary
| Step | Description | Business benefit |
| 1. Data collection & labeling | Gather high-quality, domain-specific datasets with clear input-output pairs. | Ensures the model learns relevant and accurate task-specific knowledge. |
| 2. Data preprocessing & tokenization | Convert text data into tokens compatible with the model’s architecture. | Enables efficient and accurate language processing. |
| 3. Model training (Fine-tuning) | Train the model using supervised learning: predict outputs, calculate loss, and update weights via back propagation over multiple epochs. | Improves task-specific accuracy and response quality. |
| 4. Evaluation & validation | Test the model on separate validation data to monitor performance and tune hyperparameters. | Prevents overfitting and ensures the model generalizes well. |
| 5. Deployment & monitoring | Deploy the fine-tuned model into production environments and continuously monitor its performance. | Delivers tailored AI solutions with ongoing quality assurance. |
Key benefits of SFT
- Task-specific accuracy:
SFT sharpens the model’s focus on domain-specific terminology and processes, reducing errors and improving relevance in specialized fields such as healthcare, finance, or legal. - Enhanced understanding and user experience:
Fine-tuned models better grasp unique data patterns, delivering responses that feel natural, coherent, and aligned with business expectations, which improves customer interactions and internal tool usability. - Error reduction and reliability:
Training on labeled data helps the model avoid common pitfalls and irrelevant outputs, increasing trustworthiness and reducing manual corrections. - Resource efficiency:
Compared to training from scratch, SFT requires less computational power and data, accelerating deployment and lowering costs. - Scalability and reusability:
Once fine-tuned, models can be adapted for similar tasks across projects or domains, making them reusable assets that save time and resources
Limitations of SFT
- Dependency on high-quality labeled data:
The success of SFT depends on access to well-curated, representative, and sufficiently large labeled datasets, which can be costly and time-consuming to produce. - Risk of overfitting:
Without careful validation and regularization techniques (e.g., early stopping, dropout), models can overfit to training data, reducing generalization on unseen inputs. - Limited adaptability post-training:
Fine-tuned models become static; updating knowledge or adapting to new data requires retraining or additional fine-tuning cycles. - Potential loss of general knowledge:
Excessive fine-tuning on narrow datasets may cause the model to “forget” broader language understanding learned during pre-training, a phenomenon known as catastrophic forgetting.
Common SFT applications
| Industry | Application area | Description of SFT use case | Business impact / Benefits | Example / Success story |
| Healthcare | Disease diagnosis & personalized medicine | Fine-tuning models on medical records, imaging, and clinical notes to improve diagnostic accuracy and treatment plans. | Enables precise, context-aware medical insights; supports personalized patient care; reduces diagnostic errors. | Models fine-tuned for radiology image analysis or drug discovery. |
| Clinical documentation | Adapting models to generate and summarize medical reports with domain-specific terminology. | Increases clinician productivity; ensures consistent, accurate documentation. | AI-assisted clinical note generation. | |
| Finance | Fraud detection & risk assessment | Fine-tuning on transactional data and regulatory documents to detect anomalies and assess credit risk. | Enhances fraud prevention; accelerates compliance; improves risk management. | Fine-tuned models used in credit scoring and anti-fraud systems. |
| Algorithmic trading | Customizing models to interpret market signals and execute trades based on domain-specific data. | Improves trading accuracy and responsiveness; supports automated decision-making. | Trading algorithms enhanced by domain-adapted LLMs. | |
| Retail & eCommerce | Recommendation systems | Fine-tuning on customer behavior and product data to personalize recommendations and optimize inventory management. | Boosts sales conversion; improves customer satisfaction; reduces stockouts and overstock. | Amazon’s recommendation engine improvements. |
| Sentiment analysis | Training models to understand customer feedback and social media sentiment specific to brand and product context. | Enables targeted marketing; improves customer engagement and brand reputation management. | Sentiment analysis for brand monitoring. | |
| Manufacturing | Predictive maintenance | Fine-tuning models on sensor and equipment data to predict failures and schedule maintenance proactively. | Reduces downtime; lowers maintenance costs; improves operational efficiency. | Tesla’s Autopilot uses fine-tuned vision models for real-time detection. |
| Quality control | Adapting vision models to detect defects or anomalies in production lines. | Enhances product quality; reduces waste and recalls. | Computer vision models fine-tuned for defect detection. | |
| Legal | Contract review & compliance | Fine-tuning on legal documents to extract key clauses, summarize cases, and ensure regulatory compliance. | Speeds up legal review; reduces errors; supports compliance efforts. | AI tools assisting lawyers with contract analysis. |
| Customer service | Intelligent chatbots | Training on company-specific FAQs, policies, and interaction logs to provide accurate, consistent customer support. | Improves first-contact resolution; lowers support costs; enhances customer experience. | Telecom companies fine-tuning chatbots for better support. |
| Supply chain & logistics | Demand forecasting & optimization | Fine-tuning models on historical sales and logistics data to optimize inventory and delivery schedules. | Reduces costs; improves delivery times; enhances supply chain resilience. | Retailers optimizing supply chains with AI forecasts. |
| Natural language processing (NLP) | Domain-specific language models | Adapting general LLMs to specialized language use cases such as technical manuals, scientific literature, or social media. | Improves accuracy and relevance of text generation, summarization, and translation in niche domains. | Fine-tuned GPT models for scientific research assistance. |
| Speech recognition | Accent & terminology adaptation | Fine-tuning speech models to recognize domain-specific vocabulary, accents, or noisy environments. | Enhances transcription accuracy; supports multilingual and technical use cases. | Real-time speech recognition in healthcare or legal settings. |
Best practices for SFT data preparation
Effective data preparation is the foundation of successful Supervised Fine-Tuning. The quality, representativeness, and structure of your dataset directly impact the model’s accuracy, generalization, and robustness. Below are the key best practices to follow:

1. Collect high-quality, relevant data
- Cleanliness: Remove duplicates, inconsistencies, irrelevant or noisy entries to avoid confusing the model.
- Relevance: Ensure data examples closely match the real-world inputs the model will encounter in deployment.
- Representativeness: Include diverse examples covering all important variations, edge cases, and scenarios to avoid bias and improve generalization.
- Balanced Dataset: Avoid skewed distributions that overrepresent certain classes or outcomes, which can lead to biased predictions.
2. Use proper labeling and annotation
- Clear guidelines: Define precise annotation instructions to ensure consistency across annotators.
- Expert review: Involve domain experts for labeling specialized data (e.g., medical, legal) to maintain accuracy.
- Quality control: Regularly audit labeled data to detect and correct errors or ambiguities.
3. Format data correctly
- Use supported formats such as JSON Lines (JSONL) where each line contains an input-output pair.
- Ensure inputs and outputs are clearly separated and correctly tokenized if needed.
- For multimodal data (text, images, audio), maintain consistent and compatible formatting.
4. Optimize dataset size and diversity
- Start with a minimum viable dataset (e.g., 100–1,000 examples) and scale up as needed.
- Prioritize quality over quantity; smaller, well-curated datasets outperform large noisy ones.
- Use data augmentation techniques (paraphrasing, synonym replacement, synthetic examples) to increase diversity without excessive labeling cost.
5. Split data for training, validation, and testing
- Maintain strict separation between training, validation, and test sets to avoid data leakage.
- Use validation data during training to monitor performance and prevent overfitting.
- Test on unseen data to evaluate real-world generalization.
6. Monitor and prevent overfitting
- Apply techniques such as early stopping, dropout, and weight regularization during training.
- Regularly evaluate model metrics (accuracy, loss, BLEU/ROUGE for generation tasks) on validation data.
- Adjust hyperparameters (learning rate, batch size, epochs) based on validation feedback.
7. Leverage transfer learning techniques
- Freeze lower layers of the pre-trained model that capture general knowledge to preserve foundational capabilities.
- Fine-tune only task-specific layers to reduce training time and avoid catastrophic forgetting.
8. Continuous iteration and improvement
- Fine-tuning is an iterative process; use feedback from model performance and real-world testing to refine datasets.
- Incorporate new data and edge cases discovered during deployment to keep the model updated and robust.
Reinforcement Learning from Human Feedback (RLHF): Aligning AI with Human Preferences
Reinforcement Learning from Human Feedback (RLHF) is an advanced machine learning technique that enhances pre-trained Large Language Models (LLMs) by incorporating human judgments into the training process. Unlike Supervised Fine-Tuning (SFT), which relies on fixed labeled datasets, RLHF uses human feedback to train a reward model that guides the AI to generate outputs more aligned with complex, nuanced human values and preferences.
How RLHF works
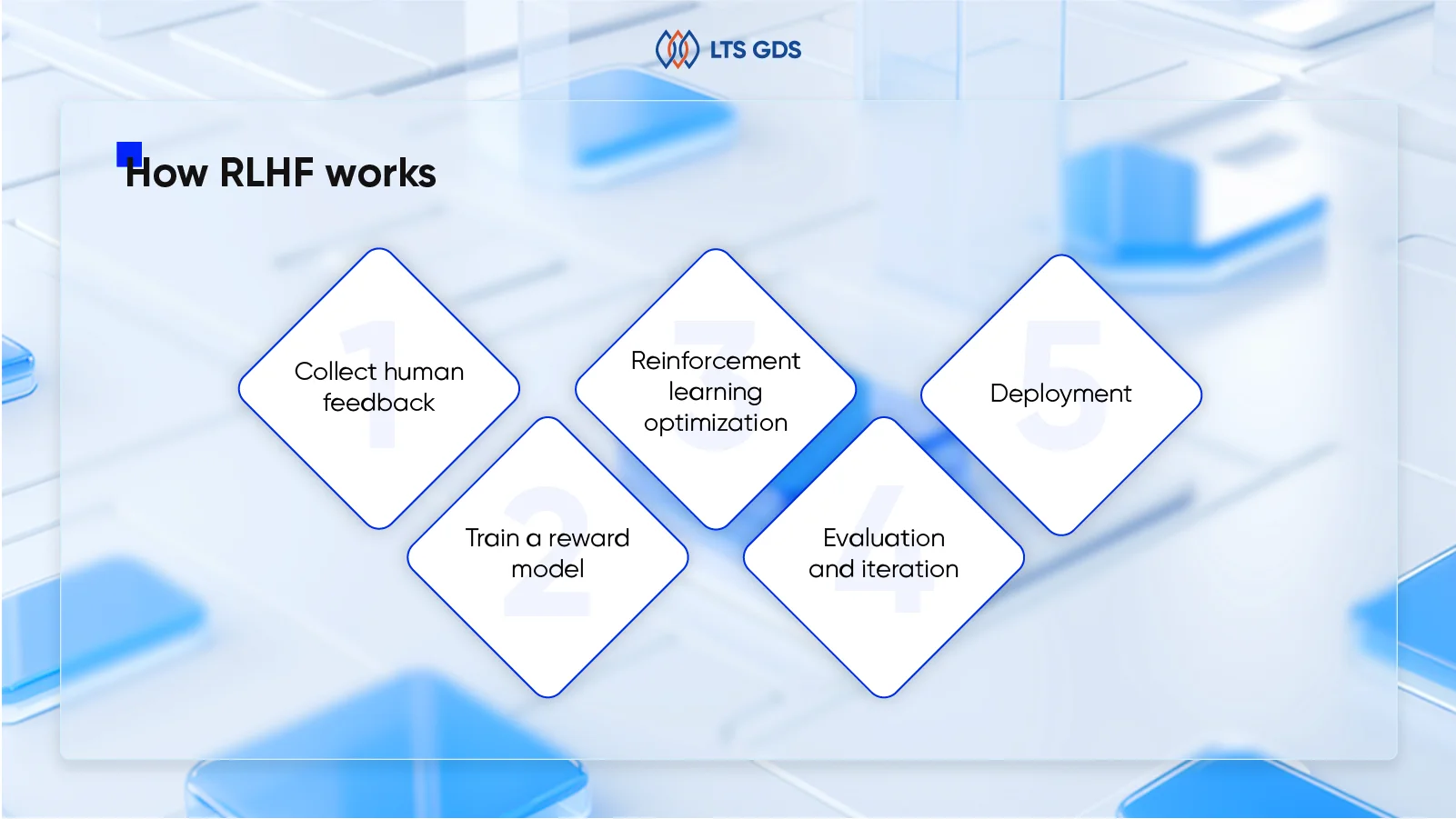
Step 1: Collect human feedback
- Human evaluators review model-generated outputs and rank or rate them according to quality, relevance, or other criteria.
- This feedback captures complex preferences that are difficult to encode explicitly.
Step 2: Train a reward model
- Using the human feedback data, a reward model is trained in a supervised manner to predict the human scores for any given output.
- This reward model effectively quantifies human preferences into a learnable function.
Step 3: Reinforcement learning optimization
- The LLM is fine-tuned using reinforcement learning algorithms (e.g., Proximal Policy Optimization) that optimize the model’s policy to maximize the reward predicted by the reward model.
- The model iteratively improves by generating outputs that receive higher reward scores, effectively aligning with human expectations.
Step 4: Evaluation and iteration
- The model’s outputs are continuously evaluated by humans and the reward model to ensure alignment and prevent undesirable behaviors.
- The process iterates, refining both the reward model and the LLM’s policy.
Step 5: Deployment
- The RLHF-tuned model is deployed in real-world applications such as conversational agents, content generation, or recommendation systems, delivering outputs that better reflect human values and preferences.
RLHF training process summary
| Step | Description | Business benefit |
| 1. Human feedback collection | Gather rankings or ratings on model outputs from human evaluators. | Captures nuanced, context-specific human preferences. |
| 2. Reward model training | Train a supervised model to predict human feedback scores. | Translates subjective human judgments into a quantitative reward function. |
| 3. Reinforcement learning | Optimize the LLM to maximize the reward model’s output using RL algorithms. | Aligns model behavior with complex human values and goals. |
| 4. Evaluation & iteration | Continuously assess and refine model outputs with human input and reward model feedback. | Ensures ongoing improvement and safety of AI responses. |
| 5. Deployment | Release the aligned model for production use in applications requiring nuanced understanding. | Provides AI outputs that are more accurate, helpful, and aligned with user expectations. |
Key benefits of RLHF
- Alignment with human values: RLHF enables models to better understand and reflect complex human preferences, including ethical and social norms.
- Improved output quality: Models trained with RLHF generate more coherent, contextually appropriate, and user-friendly responses than those trained solely with supervised learning.
- Handling ambiguity and subjectivity: RLHF excels in tasks where “correct” answers are subjective or hard to define algorithmically, such as humor, politeness, or creativity.
- Reduction of harmful content: By incorporating human feedback, RLHF helps models avoid generating biased, toxic, or inappropriate outputs.
- Continuous improvement: The iterative nature of RLHF allows models to evolve and adapt as human preferences and societal standards change.
Limitation of RLHF
- Cost and scalability of human feedback: Collecting high-quality human annotations is expensive and time-consuming.
- Bias in feedback: If the human feedback is not diverse or representative, the model may learn unintended biases.
- Complexity of training: RLHF requires sophisticated infrastructure and expertise to implement reinforcement learning algorithms effectively.
- Potential for reward model misalignment: Imperfect reward models can lead to unintended behaviors if they do not fully capture human preferences.
Common RLHF applications
| Industry | Application area | Description of RLHF use case | Business impact / Benefits | Example / Success story |
| Autonomous vehicles | Self-driving cars | RLHF helps self-driving cars learn to navigate complex, unpredictable scenarios by incorporating human feedback on driving decisions and safety. | Improves decision-making in real-world conditions, enhances safety, and enables better handling of edge cases. | Human-in-the-loop training for autonomous navigation. |
| eCommerce & streaming | Personalized recommendations | RLHF adjusts recommendation algorithms based on user interactions and feedback, leading to more accurate and personalized suggestions. | Increases user engagement, satisfaction, and conversion rates through tailored content and product suggestions. | Personalized shopping and content recommendations. |
| Healthcare | Medical diagnosis & treatment | Incorporates expert feedback to refine AI models for more accurate diagnostics and treatment recommendations from medical imaging and patient data. | Enhances diagnostic accuracy, supports personalized care, and improves patient outcomes. | AI-assisted diagnostic tools refined by clinician feedback. |
| Robotics | Complex task learning | Robots learn complex tasks safely and efficiently by integrating human guidance and corrections during training. | Increases robot adaptability, safety, and performance in dynamic environments. | Industrial robots learning assembly or manipulation tasks. |
| Conversational AI | Chatbots & virtual assistants | RLHF improves chatbots’ understanding of context, intent, and appropriateness by learning from human evaluations of responses. | Produces more natural, relevant, and safe conversations, enhancing user experience and trust. | ChatGPT and similar AI assistants fine-tuned with RLHF. |
| Gaming | AI Agents & game playing | RLHF trains game-playing agents by combining game rewards with feedback from expert players to improve strategy and performance. | Creates more challenging and human-like AI opponents, enhancing player engagement and satisfaction. | AI agents trained with human feedback in competitive games. |
| Content generation | Text, music, and image creation | RLHF guides generative models to produce content that aligns with human preferences in style, tone, and appropriateness. | Improves quality and relevance of AI-generated content, reducing manual editing and increasing creativity. | AI-generated music or art tailored by human feedback. |
| Safety & moderation | Toxicity and bias reduction | Models learn to avoid harmful, biased, or inappropriate content by incorporating human judgments on safety and ethics. | Reduces risks of harmful outputs, supports compliance, and fosters responsible AI use. | Moderation systems enhanced with RLHF for safer outputs. |
| Energy & smart systems | Grid management & optimization | RLHF helps optimize energy distribution and usage by learning from human operators’ feedback on system performance. | Improves energy efficiency, reduces costs, and supports integration of renewable energy sources. | DeepMind’s energy optimization projects using RLHF. |
Best practices for RLHF data preparation
Preparing high-quality data for Reinforcement Learning from Human Feedback (RLHF) is critical to ensure that the model learns human-aligned behaviors effectively. Unlike supervised fine-tuning, RLHF relies heavily on iterative, scalable human evaluations and preference data. Below are the key best practices derived from recent research and industry experience:

1. Collect both prompt and preference datasets
- Prompt dataset: Gather diverse and representative input prompts that the model will respond to. These prompts should reflect real-world scenarios the model will face.
- Preference dataset: Collect human feedback on model-generated outputs for these prompts, typically as rankings or ratings comparing multiple outputs. This dataset captures nuanced human preferences essential for training the reward model.
2. Ensure data quality and consistency
- Use skilled annotators and domain experts to provide accurate, unbiased feedback.
- Establish clear guidelines and training for human raters to maintain consistency across evaluations.
- Regularly audit and validate feedback data to detect and correct inconsistencies or biases.
3. Manage dataset size and distribution
- Right-size your datasets: larger datasets improve performance up to a point, but excessive data can increase costs without proportional gains.
- Ensure the distribution of prompts and feedback matches the real-world use cases to avoid poor generalization. Domain-specific datasets typically yield better results.
4. Augment and diversify data
- Use data augmentation techniques such as paraphrasing prompts or generating synthetic examples to increase diversity without excessive annotation costs.
- Include edge cases and challenging scenarios to improve model robustness and safety.
5. Structure data for efficient training
- Format data clearly separating prompts, model outputs, and human preference labels.
- Use standardized formats (e.g., JSONL) to facilitate seamless integration with training pipelines.
6. Iterative feedback and continuous improvement
- RLHF is an iterative process: continuously collect new human feedback on model outputs to refine the reward model and policy.
- Incorporate real-world usage data and edge cases discovered during deployment to keep the model aligned and up-to-date.
7. Ethical considerations and bias mitigation
- Monitor for and mitigate biases in human feedback to prevent reinforcing harmful stereotypes or unfair behaviors.
- Maintain transparency and ethical oversight throughout data collection and model training.
SFT vs RLHF: How and When to Choose the Right Training Method
Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) are two leading techniques for adapting Large Language Models (LLMs) to specific tasks and aligning them with human preferences. Each method has distinct strengths, limitations, and ideal use cases. Understanding these differences helps businesses select the most effective approach based on their goals, data availability, and resource constraints.
Overview of the methods
- Supervised Fine-Tuning (SFT):
Uses labeled datasets containing input-output pairs to directly train the model to produce desired outputs. It is straightforward, efficient, and excels at tasks with well-defined correct answers. - Reinforcement Learning from Human Feedback (RLHF):
Incorporates human feedback as a reward signal to guide the model’s behavior through reinforcement learning algorithms. It is more complex but enables alignment with nuanced human values and preferences, especially where outputs are subjective or ambiguous.
When to use each method
| Criteria | Supervised Fine-Tuning (SFT) | Reinforcement Learning from Human Feedback (RLHF) |
| Data requirements | Requires high-quality, labeled input-output pairs. | Requires human feedback in the form of rankings or ratings on outputs. |
| Task type | Best for tasks with clear, objective correct answers (e.g., translation, classification). | Best for tasks needing alignment with human preferences, ethics, or style (e.g., dialogue, content moderation). |
| Training complexity | Relatively simple and faster to train with supervised loss functions. | More complex, involving reward model training and iterative RL optimization. |
| Model behavior control | Controls output by direct supervision; limited in handling ambiguous or subjective tasks. | Enables nuanced behavior adjustment through reward signals reflecting human judgment. |
| Generalization | Can suffer from overfitting; may memorize training data. | Encourages better generalization and adaptability by optimizing reward signals. |
| Resource intensity | Lower computational cost and quicker turnaround. | Higher cost due to human feedback collection and RL training iterations. |
| Use cases | Translation, summarization, classification, structured Q&A. | Chatbots, content generation, safety alignment, personalization. |
Hybrid approaches: Combining SFT and RLHF
In practice, many successful AI systems use a hybrid training pipeline:
- Initial SFT Phase:
The model is first fine-tuned with supervised learning on labeled datasets to acquire basic task skills and language understanding. - RLHF Phase:
The model is then further refined using reinforcement learning guided by human feedback to align outputs with subtle human preferences, improve safety, and reduce undesired behaviors.
This combination leverages the efficiency and reliability of SFT with the nuanced alignment capabilities of RLHF, producing models that perform well and behave responsibly.
Summary table: SFT vs RLHF
| Aspect | Supervised Fine-Tuning (SFT) | Reinforcement Learning from Human Feedback (RLHF) |
| Training data | Labeled input-output pairs | Human feedback rankings or ratings on model outputs |
| Objective | Minimize prediction error on labeled data | Maximize reward model score reflecting human preferences |
| Complexity | Lower | Higher (requires reward model and RL algorithms) |
| Output control | Direct supervision, limited nuance | Indirect via reward signals, supports complex alignment |
| Generalization | May overfit to training data | Encourages better generalization and adaptability |
| Cost & resources | Lower | Higher due to human feedback and iterative training |
| Ideal use cases | Tasks with clear correct answers (e.g., translation, classification) | Tasks requiring alignment with human values, dialogue, content moderation |
| Training speed | Faster | Slower due to iterative feedback loops |
| Risk of undesired behavior | Lower, but can memorize biases | Can suffer from reward hacking if reward model is imperfect |
Final recommendations
- Choose SFT when:
-
- You have access to large, high-quality labeled datasets.
- The task has objective, well-defined answers.
- You need faster, cost-effective training.
- Choose RLHF when:
- The task involves subjective judgments, ethics, or style.
- You want to align the model with complex human preferences.
- You have resources to collect human feedback and support longer training cycles.
- Consider hybrid approaches:
Start with SFT to build a strong base model, then apply RLHF to refine alignment and safety, achieving the best of both worlds.
FAQ about SFT vs RLHF
1. What is the difference between Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF)?
SFT trains models on labeled input-output pairs to perform specific tasks with clear answers. RLHF, on the other hand, uses human feedback to guide the model through reinforcement learning, helping it align with more complex human preferences and ethical considerations.
2. When should I choose SFT over RLHF?
You should choose SFT if you have high-quality labeled datasets and your task has objective, well-defined answers. SFT is generally faster and requires fewer resources.
3. When is RLHF the better choice?
RLHF is better suited for tasks involving subjective judgments, style, or ethical alignment such as conversational AI or content moderation, where human preferences are complex and nuanced.
4. Can SFT and RLHF be combined?
Yes, many AI systems use a hybrid approach: first applying SFT to teach the model basic skills, then refining it with RLHF to better align outputs with human values and improve safety.
5. What are some emerging innovations that unify SFT and RLHF?
Innovations like Direct Preference Optimization (DPO) and Intuitive Fine-Tuning (IFT) aim to combine the efficiency of SFT with the alignment strengths of RLHF into unified training processes. These approaches reduce costs and improve model performance.
6. What are the key challenges in using RLHF?
RLHF requires extensive human feedback, which can be costly and time-consuming. It also requires complex training infrastructure and careful management to avoid biases and misalignment in the reward model.
7. How important is data quality in SFT and RLHF?
Data quality is critical for both methods. SFT depends on accurately labeled pairs, while RLHF relies on consistent and unbiased human feedback to train effective reward models.
8. What business benefits can I expect from using SFT or RLHF?
SFT offers fast, reliable improvements for well-defined tasks, reducing manual work and errors. RLHF produces models that better understand and align with human values, improving user satisfaction and safety in complex applications.
LTS GDS: Powering Your Enterprise AI Ambitions with Expert Data Alignment
At LTS GDS, we understand that the success of your enterprise AI projects, whether focused on advanced LLMs, coding applications, or even future multimodal AI initiatives, is intrinsically linked to the quality and precision of your data. Our specialized services, including Data Labeling for Coding LLM and comprehensive AI Data Annotation, are designed to provide the crucial foundation required for both SFT and RLHF.
We empower enterprises by offering:
- High-quality data curation: Essential for effective SFT, we ensure your datasets are accurately labeled and meticulously prepared to guide your LLMs towards precise, reliable outputs.
- Structured data for RLHF: For dynamic alignment via RLHF, we help establish the consistent, scalable evaluations and feedback loops necessary to develop robust reward models that reflect valid human preferences.
- Domain-specific expertise: Our services are tailored to the nuanced requirements of industries such as Automotive, Retail, BFSI, Construction, Healthcare, and Coding, ensuring data is annotated with deep contextual understanding.
By partnering with LTS GDS, your enterprise can streamline complex AI data processes, minimize the need for extensive in-house recruitment and training, and accelerate the development timeline for high-performing AI solutions. We bridge the gap between raw data and deployed AI, ensuring your models meet the high expectations of their intended users.
Contact GDS for a free pilot for your enterprise AI project.



