



“Global AI investment is projected to surpass $500 billion by 2027, propelled by breakthroughs in generative models, computer vision, and sophisticated machine learning applications”, (IDC)
For companies moving beyond pilots into real-world deployments, one factor that consistently sets successful AI apart is the quality of its training data.
And that data doesn’t annotate itself.
Accurate, scalable, and secure data labeling has become a foundational capability. High-quality annotated data influences not just model performance, but compliance, operational agility, and speed to market. Hence, selecting the right annotation model in-house vs outsourcing annotation can significantly affect an organization’s ability to innovate reliably and deploy AI at scale.
In this article, LTS GDS will be providing an incisive analysis of in-house vs outsourcing data annotation, highlighting the rise of hybrid models, and aligning each strategy with distinct business objectives and AI maturity phases.
Learn more about what data annotation really means and why it matters in the context of building high-performance AI systems.
Annotation Operational Models: In-House, Outsourced, and Hybrid
Data annotation can be executed through several operational models and each has its distinct advantages and challenges.
Below is a detailed exploration of each model, providing guidance on its appropriate applications, potential pitfalls, and associated costs.
In-house data annotation

When to opt for in-house data annotation?
An in-house annotation model is typically favored when control, security, and domain alignment are non-negotiable.
For organizations operating in highly regulated industries, such as pharmaceuticals, financial services, or defense, an internally managed data pipeline will greatly contribute to mitigating risk and reinforcing regulatory posture.
Enterprises may also pursue this model when data complexity or proprietary taxonomies demand deep internal domain knowledge and continuous annotation-model feedback loops.
Furthermore, embedding annotation teams directly within machine learning units can enhance iterative experimentation and create more agile development cycles.
In short, in-house annotation is best suited for organizations that require:
- Maximum control over data security and privacy, especially when handling sensitive or proprietary information such as healthcare records, financial data, or government documents.
- Close collaboration between annotators and AI teams, facilitating rapid feedback loops and iterative improvements.
- Highly specialized domain expertise that is difficult to outsource effectively, such as medical imaging or autonomous vehicle sensor data.
Challenges of in-house data annotation
However, running annotation internally comes with a steep operational curve. Internal teams often face:
- High fixed overheads, including recruitment, salaries, and workspace management.
- Attrition risks, especially in high-churn, repetitive labeling environments.
- Training burden – annotation quality hinges on domain fluency and ongoing education.
- Scalability bottlenecks – responding to surges in annotation volume often proves difficult without elastic workforce capabilities.
Without robust infrastructure and process maturity, quality inconsistency, delivery slippage, or burnout among annotators can erode returns on internal investment.
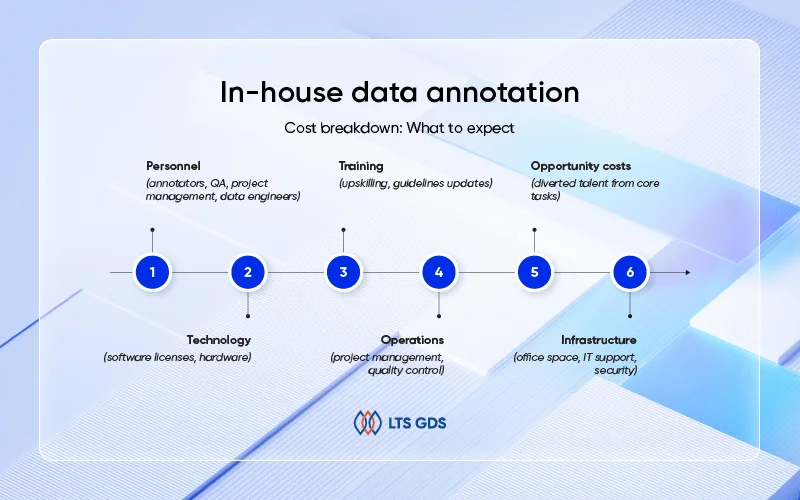
Cost breakdown: What to expect
Building and maintaining an in-house annotation capability entails significant fixed and indirect costs that extend beyond the immediately visible expenses. Organizations opting for this model must consider:
Direct cost components
- Personnel: Recruitment, salaries, benefits, and retention costs for annotators, quality assurance specialists, project managers, data engineers, and domain experts.
- Technology: Licensing fees for annotation platforms, data management tools, visualization software, and hardware investments including servers and storage devices.
- Training: Continuous investment in upskilling staff, compliance training, and annotation guideline updates to maintain annotation quality and adapt to evolving AI requirements.
Indirect and hidden costs
- Operational management: Resources dedicated to project planning, workflow coordination, quality control, and performance monitoring.
- Opportunity costs: The diversion of skilled personnel from core business functions to annotation activities, potentially impacting overall organizational productivity.
- Infrastructure: Expenses related to office space, utilities, IT support, and physical and network security measures.
Final verdict
In-house annotation is best suited for enterprises with stable, ongoing annotation needs that demand stringent data security and quality control. However, the total cost of ownership often exceeds initial estimates due to indirect costs and operational complexities, necessitating careful cost-benefit analysis.
Outsourcing data annotation
When to opt for outsourcing data annotation?
Outsourcing becomes an attractive lever when speed-to-market, operational efficiency, and cost optimization are top-line objectives. Counting on a dedicated annotation company allows enterprises to rapidly scale annotation volume, access specialized talent pools, and tap into advanced labeling technologies without upfront infrastructure commitments.

Challenges
That said, outsourcing is not without its friction points:
- Dependency on vendor workflows, which can delay iterations and erode agility.
- Security and confidentiality risks, especially when annotating proprietary or regulated data.
- Communication barriers, including misalignment on annotation guidelines, taxonomy drift, and quality discrepancies.
Without well-defined service level agreements (SLAs), proactive QA processes, and collaborative governance models, the benefits of outsourcing can be undercut by quality degradation or delivery lags.
Cost breakdown: What to expect
Outsourcing annotation services shifts much of the cost burden to a variable model, aligning expenses with project scope and volume. Key considerations include
Common pricing models
- Fixed price: A predetermined fee for a clearly defined project scope, facilitating budget predictability but limited flexibility.
- Hourly rate: Charges based on actual time spent, suitable for projects with evolving requirements but potentially less predictable costs.
- Per-label/Unit pricing: Payment per annotated data unit, ideal for large-scale, high-volume annotation tasks with clear deliverables.
- Subscription/retainer: Regular fees for ongoing annotation services, supporting continuous data labeling needs.
Additional and hidden costs
- Contract negotiation: Legal and administrative expenses involved in drafting and finalizing service agreements and SLAs.
- Vendor management: Time and resources allocated to vendor oversight, coordination, and performance evaluation.
- Communication overhead: Costs related to meetings, updates, feedback cycles, and potential delays due to geographic or cultural differences.
- Quality assurance and rework: Expenses incurred from additional quality checks and correcting annotation errors.
Final verdict
Outsourcing offers scalability and access to specialized expertise with lower upfront investment but requires vigilant management of vendor relationships and quality control to avoid cost overruns and data security risks.

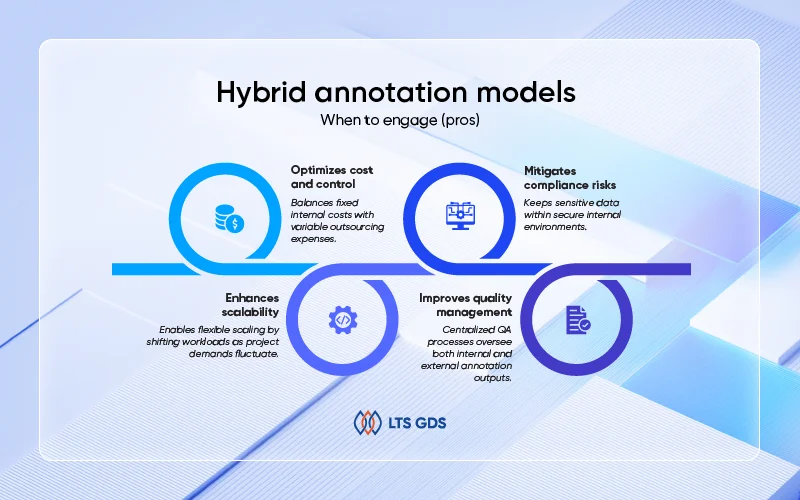
Hybrid annotation models
What is a hybrid annotation?
The hybrid annotation model blends internal control with external scalability, offering the best of both worlds, especially for organizations navigating heterogeneous data types or inconsistent sensitivity levels.
Under this model, internal teams may handle:
- High-risk, sensitive, or IP-critical data
- QA and guideline development
- Iterative feedback loops for fine-tuning model performance
Meanwhile, external vendors are leveraged for:
- Volume-heavy, less sensitive annotations
- Edge cases that benefit from specialized annotators
- Rapid expansion during model training sprints or go-to-market pushes
This hybrid approach enables leaders to maintain strategic oversight while unlocking operational elasticity.
Operational requirements
Successfully orchestrating a hybrid model requires:
- Data classification: Rigorous segmentation of data by sensitivity and complexity to allocate annotation appropriately.
- Unified quality assurance: Centralized QA frameworks for ensuring consistent standards across teams.
- Integrated annotation platforms: Tools supporting seamless collaboration and data flow between internal and external annotators.
- Clear governance: Defined roles, responsibilities, and communication protocols to manage hybrid workflows effectively.
Additionally, cross-functional collaboration between data science, legal/compliance, and vendor management functions is vital to form alignment with internal risk frameworks and regulatory expectations.
Use cases where hybrid excels
When orchestrated well, hybrid annotation becomes a strategic differentiator in building enterprise-grade AI systems in the light of its control level, flexibility, scalability and efficiency. Keep scrolling for recommendations for handling hybrid models.
| Industry | In-house focus | Outsourced task | Example |
| Healthcare & Life sciences | Sensitive clinical data (e.g., diagnostics, patient records) | Public datasets, anatomical segmentation | Internal team labels radiology scans; vendors annotate general anatomy data |
| Financial services | Regulated data (fraud detection, risk models) | Customer interaction, document classification | Internal team flags transaction anomalies; vendors label support logs |
| Retail & eCommerce | Brand-sensitive assets, product narratives | Bulk catalog data, sentiment analysis | In-house curates flagship content; vendors handle customer reviews |
| Autonomous vehicles | Critical edge cases, safety scenarios | Large-scale driving footage, sensor data | Safety-critical frames labeled internally; highway footage sent to the vendor |
| Enterprise NLP | Proprietary/internal documents (legal, strategic) | General NLP tasks, multilingual corpora | Legal documents reviewed internally; summarization outsourced |
Key Factors to Consider When Choosing an Annotation Model
Data sensitivity & regulatory compliance
Data sensitivity and compliance requirements directly dictate the level of control needed over annotation workflows.
For instance, industries such as healthcare, finance, and government face stringent regulations that mandate data sovereignty and auditability. Breaches or non-compliance can result in legal penalties, reputational damage, and loss of stakeholder trust.
Insight
A certified hybrid model that combines in-house control for sensitive subsets with vetted outsourcing for non-sensitive data can balance compliance and scalability.
AI, ML and LLM companies should make sure vendors hold certifications like ISO 27001, SOC 2, or GDPR compliance for outsourced tasks.
Internal capabilities & organizational readiness
An organization’s existing talent, tools, and processes determine its ability to execute annotation efficiently. Teams lacking domain expertise or mature workflows risk delays, inconsistent quality, and higher costs.
For example, a startup without NLP specialists might outsource multilingual text annotation, while an enterprise with robust infrastructure could adopt hybrid models to balance control and cost.
Insight
Readiness assessments prevent overcommitment to unsustainable in-house efforts or underqualified vendors.

AI/ML project stage and scale
Annotation needs evolve alongside AI maturity. Check out the table below to pick up the right model based on the project status.
| Growth stage | Recommended model | Rationale |
| Early-stage / Proof of Concept (POC) | In-house or Hybrid | Tight control for iterative feedback and bias mitigation |
| Scaling phase / growth | Outsourcing or Hybrid | Rapid scalability and cost efficiency for high-volume tasks |
| Mature AI deployment | Hybrid | Balances cost, quality, and compliance for optimized workflows |
| Highly regulated or sensitive data | In-house or certified Hybrid | Ensures data sovereignty and auditability |
| Complex annotation needs | Specialized outsourcing or Hybrid | Leverages niche expertise (e.g., LiDAR, multilingual NLP) |
Insight
Misaligning annotation strategies with project stages can inflate costs or delay deployments. For instance, outsourcing complex POC data may introduce quality risks, while in-house labeling bulk datasets slows scaling.
Operational excellence: Evaluation criteria & best practice
Regardless of whether an organization adopts an in-house, outsourced, or hybrid model, long-term success depends on a well-defined evaluation framework and disciplined execution.
Below is a consolidated guide outlining key evaluation criteria to ensure the annotation strategy delivers:
| Criteria | In-house annotation | Outsourcing annotation | Hybrid annotation |
| Cost structure | High fixed costs: salaries, training, infrastructure | Variable costs: pay-per-label or project based pricing | Balanced: fixed internal costs + variable outsourcing expenses |
| Control & security | – Maximum control
– Best for sensitive data and compliance needs |
– Lower control
– Depends on vendor security protocols |
– Segmented control
– Sensitive data for in-house, others outsourced |
| Quality assurance | – Direct oversight
– Customizable QA processes |
– Dependent on vendor QA
– Requires rigorous SLAs and monitoring |
Centralized QA integrating both in-house and vendor outputs |
| Scalability | Limited by hiring/ training speed; slower to scale | Rapid scaling possible via vendor resources | Flexible scaling by distributing workloads based on sensitivity |
| Speed to market | Slower ramp-up due to recruitment and onboarding | Faster deployment with established vendor teams | Moderate; combines speed of outsourcing with control of in-house |
| Talent availability | Requires internal domain experts and annotation specialists | Access to diverse, specialized global talent | Combines internal expertise with external specialized resources |
| Compliance & governance | Easier to enforce internal policies and audit trails | Requires vendor certifications (ISO, SOC 2, HIPAA) | Hybrid governance framework to ensure compliance across teams |
| Risk exposure | – Lower risk of data leakage- – Higher operational risk | – Higher risk of data exposure
– Dependent on vendor security |
Mitigated risk through data segmentation and governance |
Insight:
In-house or outsourcing data annotation or hybrid model, each has its own merit and poses challenges that businesses should beat off to make the most use of the selected model. Here come execution best practices:
| Internal teams | Outsourcing partnerships | Hybrid setups |
| 1. Combat turnover: Implement gamified training and career progression paths.
2. Leverage automation: Use AI-assisted tools (e.g., CVAT auto-labeling) to reduce manual effort by 30 – 40%. 3. Audit frequently: Conduct monthly QA audits to catch labeling drift. |
1. SLAs as non-negotiables: Demand 99%+ accuracy rates and real-time dashboards for progress tracking.
2. Pilot projects: Test vendors with 1.000 – 5.000 samples before full commitment. 3. Cultural alignment: Assign bilingual project managers to bridge communication gaps. |
1. Clear role definition:
– In-house teams handle sensitive data and complex edge cases. – Vendors manage bulk, routine tasks (e.g., image tagging). 2. Unified QA ownership: Centralize quality checks using platforms such as Aquarium Learning. 3. Seamless integration: Use APIs to sync data between internal tools (Labelbox) and vendor platforms (LTS GDS, Scale AI, etc.). |
Check LTS GDS’s QA process here
How to Evaluate and Select the Right Data Annotation Partner (If Outsourcing)
For organizations leaning towards outsourcing, a structured evaluation process is essential. From assessing internal readiness to vetting partner capabilities, a detailed selection framework ensures alignment with technical, security, and operational needs.

To support your decision-making, we’ve developed a practical framework in How to evaluate and select the right data annotation partner. The article walks through internal readiness checklists, partner qualification criteria, and performance benchmarks.
For additional insights, don’t miss our curated roundup of the top 9 data annotation companies and top 10 best image annotation companies currently leading the field.
Why Choose LTS GDS for Your Data Annotation Needs?
LTS GDS delivers a robust annotation model designed for enterprise deployment, combining process maturity with vertical-specific expertise to support clients at every AI development stage.

- Quality-driven approach
High-quality training data starts with high-quality processes. Our four-step annotation workflow, combined with rigorous QA protocols, has achieved up to 99% accuracy and earned us DEKRA’s Certificate of Conformity for Data Labeling. We’ve delivered large-scale, complex datasets across industries without compromising quality.
- Data security first
LTS GDS meets the highest global data protection standards. We are ISO/IEC 27001 certified, GDPR compliant, and enforce strict NDA protocols to keep your data safe – essential for industries like healthcare, finance, and government.
- Vertical expertise
From healthcare and autonomous vehicles to finance, eCommerce, and manufacturing, we bring deep domain knowledge that reduces onboarding time and enhances annotation relevance.
- Dedicated teams
Projects are managed by multi-tiered teams, pairing experienced project leads with well-trained annotators. This structure enhances communication flow, scalability, and quality governance, providing seamless integration with internal AI teams and agile response to scope changes.
- Cost-effective scalability
Based in Vietnam, we combine competitive labor costs with flexible pricing models, helping global teams scale quickly without losing control over cost, quality, or timelines.
No lock-in, just confidence
Start with a free pilot to validate quality, assess workflows, and ensure alignment before scaling. This lets your team evaluate real output with zero commitment.
FAQs about In-house vs Outsourcing Data Annotation
1. What is data annotation and why is it essential for AI and machine learning?
Data annotation is the process of labeling raw data (text, image, video, etc.) to train AI/ML models. It enables supervised learning by helping models recognize patterns and make accurate predictions. High-quality annotation boosts model accuracy, performance, and reliability.
2. How do I decide whether to keep data annotation in-house or outsource it?
- Choose in-house data annotation for sensitive data, strict compliance needs, or when internal expertise is available.
- Opt for outsourcing to reduce costs, scale quickly, and access specialized tools and talent.
- Consider a hybrid model for balance – internal control for critical tasks, external support for volume work.
3. What are the main risks when outsourcing data annotation, and how can they be mitigated?
- Quality inconsistency → Use vendors with strong QA processes and pilot projects.
- Data security concerns → Choose partners with ISO 27001, GDPR compliance, and NDAs.
- Communication gaps → Ensure clear SLAs, regular feedback loops, and aligned workflows.
4. Cost of in-house vs outsourced data annotation
In-house data annotation:
- Requires high upfront costs for infrastructure, hiring, and training.
- Involves ongoing fixed expenses such as salaries, benefits, and team management.
- May lead to hidden costs from slow ramp-up, staff turnover, or inconsistent quality control.
- Best suited when data sensitivity, domain expertise, and control are critical.
Outsourced data annotation:
- Offers flexible pricing models (pay-per-label, subscription, project-based).
- Reduces operational costs through access to offshore talent and ready-made tools.
- Includes scalable resources and built-in QA without internal overhead.
- Ideal for large-scale projects with standardized tasks or short timelines.
5. What are the best data annotation services/ providers?
Top data annotation providers offer domain expertise, secure infrastructure, scalable teams, and high accuracy, with leading names including LTS GDS, Labelbox, Appen, and Scale AI. When choosing a vendor, focus on quality assurance, compliance, pricing transparency, and technical capabilities to ensure optimal outcomes.
Conclusion: Rethinking What’s Optimal for Your AI Strategy – In-house vs Outsourcing Data Annotation
There’s no one-size-fits-all answer when it comes to in-house vs outsourcing data annotation. Each option offers distinct strengths depending on your team’s priorities, be it control, agility, compliance, or operational efficiency. While building internal capabilities ensures greater oversight and data privacy, partnering with external experts can unlock faster execution, domain-specific skills, and scalable support. Increasingly, many organizations are blending both to address evolving project demands without compromising on quality or speed.
Making the right decision starts with asking the right questions:
- Does our team have the capacity and infrastructure?
- Are we equipped to meet regulatory expectations?
- Will this approach support long-term product goals?
At LTS GDS, we help businesses move forward with confidence. Whether it’s full-service support or hybrid collaboration, we build flexible models that grow with your ambitions.
Contact us now!


