Ryan Le
Gen AI Manager
Coding, STEM & Engineering, Physical AI & Robotics




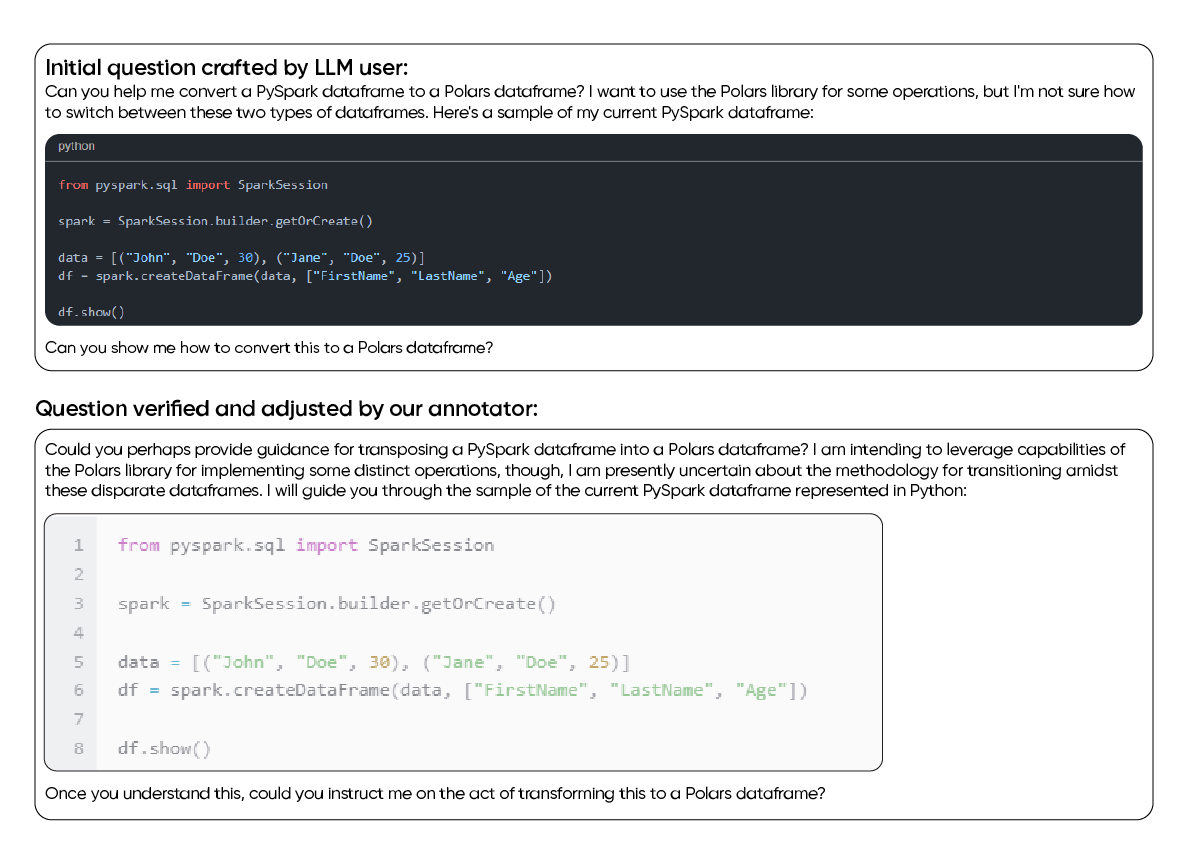
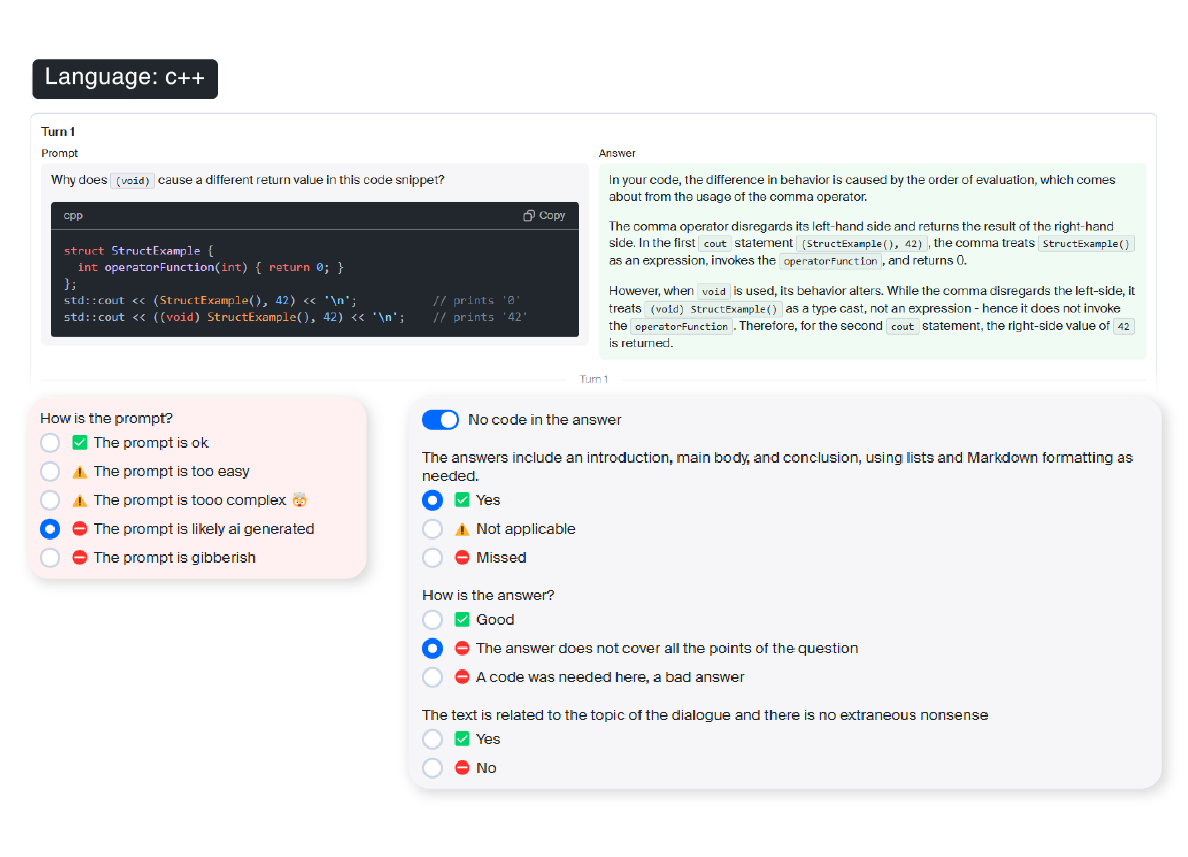

 LTS GDS는 대규모의 검증된 데이터셋을 제공하여 코딩 모델의 견고한 기반을 구축합니다. 이를 통해 다양한 언어 및 도메인에 걸쳐 프로그래밍 문법, 패턴, 그리고 범용적 추론 능력을 효과적으로 학습할 수 있습니다.
LTS GDS는 대규모의 검증된 데이터셋을 제공하여 코딩 모델의 견고한 기반을 구축합니다. 이를 통해 다양한 언어 및 도메인에 걸쳐 프로그래밍 문법, 패턴, 그리고 범용적 추론 능력을 효과적으로 학습할 수 있습니다.
제공 서비스

LTS GDS는 코드 생성, 소스 코드 분석, 알고리즘 설명 등 코딩 LLM의 핵심 역량 강화를 위한 미세 조정 데이터셋을 제공합니다.
제공 서비스
LTS GDS의 전문가들은 인간 피드백 기반 강화학습(RLHF)을 활용하여 프로그래밍 맥락에서 모델이 생성한 응답을 평가하고 순위를 산정합니다. 평가 기준은 정확성, 알고리즘 효율성, 실행 가능성, 언어 규정 준수 여부 등으로 구성됩니다.
제공 서비스
LTS GDS는 서로 다른 모델 버전 간 비교 또는 기존 벤치마크 대비 A/B 비교 방식을 통해 프로그래밍 태스크에서의 모델 성능을 평가하는 데이터 레이블링 서비스를 제공합니다.
제공 서비스
LTS GDS는 편향(Bias), 환각(Hallucination), 유해 콘텐츠 생성 등 프로그래밍 모델의 잠재적 취약점을 체계적으로 식별합니다.
제공 서비스


초기 단계에서 GDS의 검증된 엔지니어들이 프로젝트 요구사항을 정의합니다. 고객과의 초기 교육 세션을 진행하고, 프로젝트 가이드라인 문서를 명확히 하기 위해 Q&A 세션을 실시합니다.

내부 팀과 벤더 팀을 포함한 프로젝트 팀을 구성한 후, 필요한 프로그래밍 언어에 따라 작업을 배정합니다. 가이드라인을 명확히 하고 질문에 답변하기 위해 내부 딜리버리 팀과 벤더 팀 모두를 대상으로 교육을 진행합니다. 마지막으로, 양측 팀과 회의를 진행하여 실행 방식에 대한 정렬을 맞춥니다.

파일럿 작업을 수행하여 고객에게 전달합니다. 피드백을 받은 후 내부 및 외부 딜리버리 팀과 후속 회의를 진행합니다. 이 단계에서 확인된 새로운 시나리오나 엣지 케이스를 반영하여 가이드라인을 업데이트합니다.


불명확한 설명, 숨겨진 요구사항 등 외부 요인으로 인한 반려 건은 고객에게 보고하여 명확한 지침을 요청합니다. 또한, 실행 과정에서 발견된 내부 오류를 해결하기 위해 격일로 회의를 진행합니다.










정교한 Supervised Fine-tuning(SFT) 데이터셋을 구축하기 위해 엄격한 QA 프로세스를 적용하며, 최대 99% 정확도를 달성하도록 설계된 고성능 코딩 모델 학습용 데이터셋을 제공합니다.

SQL, Python, C#, JavaScript, TypeScript, Bash, .NET, Scala 등 다양한 언어에 능통한 100명 이상의 숙련된 개발자가 참여하여, LLM이 빠르고 논리적이며 오류 없는 코드를 생성할 수 있도록 지원합니다.

LTS GDS는 대규모 프로젝트를 위해 전문 PM과 사내 팀 및 파트너 네트워크를 활용한 최대 200 man-months 규모의 전담 팀을 2주 이내에 구성할 것을 보장합니다.
베트남 아웃소싱 시장의 비용 경쟁력과 우호적인 세제 정책을 기반으로, 글로벌 기업은 최적의 예산으로 사전 학습된 모델을 코딩 특화 LLM으로 최적화할 수 있는 IT 전문가를 확보할 수 있습니다.

OSWorld, GAIA, SWE-bench, COCO, MMMU 등 주요 산업 벤치마크의 표준 요건에 맞춘 맞춤형 데이터 레이블링 워크플로우를 설계합니다.

공개 벤치마크 테스트 데이터가 학습 파이프라인에 유입되는 것을 방지하는 엄격한 필터링 프로토콜을 적용하여 모델 무결성과 평가 신뢰성을 보호합니다.

도메인 전문가를 활용하여 정교한 추론 능력과 분야별 정확도를 보장함으로써, 학습 데이터와 벤치마크 성과 간의 격차를 해소하고 SOTA AI 모델 구현을 지원합니다.