



Semantic segmentation emerges as a game changing technology, transforming how businesses across industries approach visual data analysis. From enabling autonomous vehicles to navigate safely through complex traffic scenarios to helping radiologists detect minute abnormalities in medical scans, semantic segmentation is revolutionizing decision making processes that rely on visual accuracy.
Yet despite its transformative potential, semantic segmentation remains one of the most misunderstood technologies in the AI landscape. Many organizations struggle to differentiate it from basic object detection, underestimate implementation complexities, or fail to identify the right use cases where it delivers maximum ROI.
In this article, we’ll demystify the topic: what is semantic segmentation, how this technology works, examine real-world applications across industries, and provide practical insights for successful implementation.
What is Semantic Segmentation?
Semantic segmentation represents the pinnacle of image understanding technology, where every pixel in an image receives a semantic label indicating what object or region it represents. This process goes far beyond simple object detection or classification, providing a complete understanding of visual scenes at the most granular level possible.
To be more specific, the term “semantic” refers to the meaning or interpretation of visual elements, while “segmentation” describes the process of dividing images into distinct regions. Together, semantic segmentation creates a detailed map where each pixel is assigned to a specific class or category, such as “person,” “car,” “building,” or “sky.”
Semantic segmentation = Label each pixel in the image with a category label, don’t differentiate instances, just care about the pixels.
For instance, the below picture shows a segmentation class of distinct objects such as sky, house, grass, and cat.
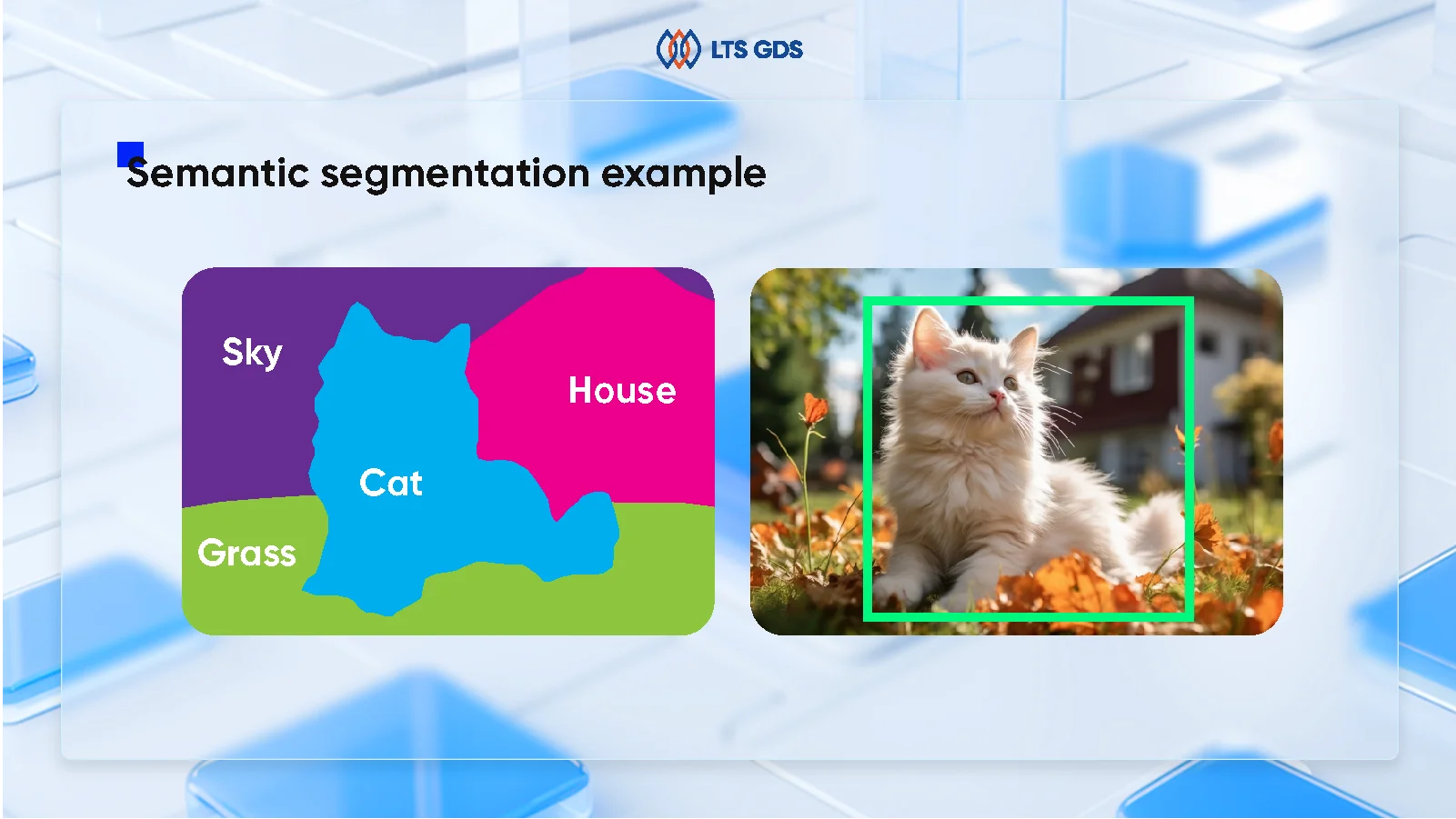
Semantic segmentation vs other computer vision tasks
Semantic segmentation differs fundamentally from other computer vision approaches. Whereas object detection identifies and locates objects within bounding boxes, and image classification assigns labels to entire images, semantic segmentation provides pixel-perfect boundaries and classifications.
The technology builds upon deep learning algorithms that break down images into meaningful segments. Each pixel gets categorized according to its semantic class – whether it represents a person, vehicle, building, vegetation, or background element. This granular approach enables machines to understand visual information much like the human brain processes complex scenes.

Think of it this way: while object detection might point out that there’s a cat in an image, semantic segmentation pinpoints exactly which pixels make up that cat, distinguishing it from the grass, sky, and surrounding objects.
Modern semantic segmentation systems utilize sophisticated deep learning architectures, including convolutional neural networks (CNNs) and transformer-based models (which we’ll talk about in later parts of this article). These systems learn to recognize patterns, textures, shapes, and spatial relationships that distinguish different objects and regions within images.
The Three Pillars of Image Segmentation
To truly grasp the value proposition, it’s essential to understand how semantic segmentation fits into the broader computer vision landscape. The field encompasses three main segmentation approaches, each serving different business needs:
- Instance segmentation focuses on countable objects, breaking down individual instances of the same class. For example, it would identify three separate cars in a parking lot, giving each vehicle its own unique identifier. This approach works well for inventory management and object tracking applications.
- Panoptic segmentation combines both semantic and instance segmentation, delivering comprehensive scene understanding. It assigns every pixel both a semantic label and, where applicable, a unique instance identifier. This dual approach proves invaluable for complex scenarios requiring complete visual context.
- Semantic segmentation classifies every pixel according to its semantic meaning without distinguishing between individual instances. While it might label all cars with the same class identifier, it provides the precise boundaries that businesses need for detailed analysis.
To explore these segmentation approaches in detail, including practical examples and implementation strategies, visit our comprehensive guide on image segmentation types.
How Semantic Segmentation Works?
Understanding how semantic segmentation works doesn’t require deep technical expertise. Think of it as teaching a computer to understand images the way humans do, by breaking down complex scenes into meaningful parts. Here’s a simplified overview of the process:
The 5 step semantic segmentation process
Step 1: Image input and preprocessing
The process begins when an image enters the system. Just like preparing a document for analysis, the system first standardizes the image – adjusting size, brightness, and format to ensure consistent processing. This preprocessing step is crucial for maintaining accuracy across different image sources and conditions.
Step 2: Feature detection and analysis
The AI system examines the image layer by layer, similar to how a detective analyzes a crime scene. It starts by identifying basic elements like edges, shapes, and textures, then progressively recognizes more complex patterns like object parts and spatial relationships. This hierarchical analysis allows the system to understand both fine details and broader context.
Step 3: Pattern recognition and classification
Using its trained knowledge base, the system compares detected features against millions of examples it has learned from. This is similar to how a doctor diagnoses symptoms by comparing them to cases they’ve studied. The AI identifies what each region of the image represents, distinguishing between cars, people, buildings, sky, and other objects.
Step 4: Pixel-level assignment
Here’s where semantic segmentation shows its power. Instead of just identifying “there’s a car in this image,” the system assigns every single pixel to a specific category. Each pixel gets labeled as “car,” “road,” “person,” “building,” or whatever object it belongs to. This creates a detailed map of the entire image.
Step 5: Output generation and refinement
The final step produces a segmented image where each region is clearly defined and labeled. The system performs quality checks and refinements to ensure boundaries are accurate and classifications are consistent. The result is a comprehensive understanding of the image that machines can act upon.
The technology behind the process
Deep learning foundation
Semantic segmentation models use complex neural networks to accurately group related pixels together into segmentation masks and correctly recognize the real-world semantic class for each group. These systems require extensive training on large, annotated datasets where human experts have manually labeled every pixel.
The training process involves showing the algorithm thousands of examples, allowing it to learn patterns and relationships between visual features and their corresponding semantic meanings. Through techniques like backpropagation and gradient descent, the model continuously refines its understanding until it can accurately classify new, unseen images.
Network architectures
Several groundbreaking architectures have shaped modern semantic segmentation:
Fully Convolutional Networks (FCNs) replaced traditional flat layers with convolutional blocks, enabling end-to-end training for pixel-level predictions. These networks address the inefficiencies of sliding window approaches by reusing shared features and processing entire images simultaneously.
U-Net architecture introduced the encoder-decoder paradigm that has become standard in segmentation tasks. The encoder progressively reduces image resolution while extracting features, and the decoder reconstructs the full-resolution segmentation map. This architecture proves particularly effective in medical imaging applications.
DeepLab models developed by Google incorporate atrous (dilated) convolutions to maintain high resolution while expanding the receptive field. This innovation allows models to capture both fine details and broader context simultaneously.
Vision transformers represent the latest evolution, leveraging attention mechanisms to model global relationships without the local limitations of traditional convolutions. These transformer based models address limitations of fully convolutional networks by capturing global image features that may be necessary for solving segmentation tasks in particular domains.
Semantic Segmentation Real World Use Cases
Autonomous vehicles and transportation
The automotive industry represents one of the most demanding applications for semantic segmentation. Self-driving cars use semantic segmentation to see the world around them and react to it in real-time, separating what the car sees into categorized visual regions such as lanes, other cars, and intersections. The technology enables vehicles to navigate safely and respond to unexpected events like pedestrians or sudden braking.
Learn more about how we support automotive AI development in our guide to data annotation in the automotive industry.
Healthcare and medical imaging
Medical applications demand the highest levels of accuracy, making semantic segmentation invaluable for diagnostic imaging. Medical procedures such as CT scans, X-rays, and MRIs rely on image analysis, and semantic segmentation models are achieving results similar to medical professionals. The technology can detect anomalies, outline tumor boundaries, and even suggest potential diagnoses.
In radiology, semantic segmentation helps identify specific anatomical structures, measure organ volumes, and track disease progression over time. The precision offered by pixel-level analysis proves crucial when millimeter accuracy can mean the difference between successful treatment and missed diagnosis.
Agriculture and precision farming
Modern agriculture increasingly relies on computer vision for crop monitoring and automated farming operations. Farmers use AI and semantic segmentation to detect infestations in crops and automate pesticide spraying, with computer vision identifying which parts of fields are potentially infected.
Semantic segmentation enables drones and ground-based systems to distinguish between healthy crops, diseased plants, weeds, and soil. This granular analysis supports precision agriculture techniques that optimize resource usage while maximizing yields.
Manufacturing and quality control
In manufacturing environments, semantic segmentation powers automated quality inspection systems. The technology can identify defects, measure component dimensions, and ensure products meet specifications. Unlike human inspectors who may experience fatigue or inconsistency, semantic segmentation provides reliable, 24/7 quality monitoring.
Retail and eCommerce
The retail sector leverages semantic segmentation for inventory management, virtual try-on experiences, and automated product cataloging. Popular filters and features on apps like Instagram and TikTok use semantic segmentation to identify objects so chosen filters or effects can be applied. This same technology enables virtual fitting rooms and personalized shopping experiences.
Technical Implementation Challenges and Solutions

Data quality and annotation requirements
High quality training data forms the foundation of effective semantic segmentation models. Pixel-accurate annotations are required for semantic segmentation, and creating them is a tedious and expensive project. The annotation process requires human experts to label every pixel in thousands of images, making it one of the most labor-intensive aspects of computer vision projects.
At LTS GDS, we understand these challenges and offer comprehensive data annotation services to support your business’ semantic segmentation projects. Our experienced annotation teams can handle projects of any scale, ensuring the high quality training data your models need to succeed.
Computational requirements
Semantic segmentation models demand significant computational resources for both training and inference. The pixel-level processing required for high-resolution images can strain standard hardware configurations. Organizations must carefully balance model complexity with available computing resources and real time performance requirements.
Cloud computing platforms and specialized AI hardware help address these challenges, but proper architectural planning remains essential. Our development teams work closely with clients to optimize model architectures for their specific hardware constraints and performance requirements.
Model optimization and deployment
Deploying semantic segmentation models in production environments requires careful optimization for speed, accuracy, and resource efficiency. Techniques like model quantization, pruning, and knowledge distillation can reduce model size and inference time while maintaining acceptable accuracy levels.
Edge deployment presents additional challenges, as models must operate within the constraints of mobile devices or embedded systems. Our engineering teams specialize in optimizing models for various deployment scenarios, from cloud-based services to edge computing applications.
Key Factors for Successful Semantic Segmentation

1. Accuracy vs. speed
Different applications prioritize different performance metrics.
- In medical imaging, even small segmentation errors can lead to serious consequences. Maximum accuracy is non negotiable.
- On the other hand, real time video processing (e.g., autonomous vehicles or surveillance systems) may require faster inference speeds, even if it means sacrificing some precision.
Insight
Choosing the right architecture and model complexity depends on your specific use case. A clear understanding of these trade-offs allows your team to make informed decisions.
2. Dataset quality and fit
Semantic segmentation models require pixel-level annotations and creating these datasets is time consuming and expensive.
- If your domain aligns with popular segmentation datasets, using pre-trained models can significantly accelerate development.
- For specialized tasks, you’ll need custom labeled data, tailored to your use case.
Insight
The quality, quantity, and diversity of your training data will directly affect model performance. Invest early in the right data strategy.
3. Integration with business systems
No AI model is useful in isolation. It must seamlessly integrate into your existing workflows, tools, and infrastructure.
- Consider API compatibility, data formats, and downstream processing requirements.
- Poor integration planning can lead to delays, rework, and user adoption issues.
Insight
Think beyond the model and focus on system design and how your team will actually use the output.
4. Expert implementation matters
Semantic segmentation is technically demanding. Teams without deep computer vision experience often face:
- Inefficient model selection
- Poor training pipelines
- Over or under optimized models for production
Insight
Leveraging experienced professionals can prevent costly trial and error and accelerate time to deployment. Industry best practices and lessons learned from real-world deployments make a big difference.
5. Long term maintenance and optimization
Model performance tends to degrade over time as data distributions shift (data drift).
- Regular retraining and performance monitoring are necessary to maintain accuracy.
- Without a long-term strategy, your segmentation system may lose its effectiveness quickly.
Insight
Treat your model like a product, not a one time project. Ongoing maintenance is essential.
6. Internal enablement and knowledge transfer
Relying entirely on external vendors creates long term dependency.
- Your internal teams should understand the model, know how to retrain it, and troubleshoot issues
- Invest in training and documentation so the knowledge stays within your organization
Insight
Empowering your team ensures sustainability and better return on investment.
For organizations seeking comprehensive support for their computer vision projects, explore our data annotation outsourcing services and discover why we’re recognized among the top data annotation companies in the industry.
Future Trends and Emerging Technologies
The semantic segmentation landscape continues evolving rapidly, with several trends shaping its future development.
Transformer based architectures
Vision transformers are increasingly replacing traditional convolutional networks for semantic segmentation tasks. These architectures excel at capturing long range dependencies and global context, often producing superior results on complex datasets. As transformer technology matures, we expect to see continued improvements in segmentation accuracy and efficiency.
Few-shot and zero-shot learning
Emerging techniques enable semantic segmentation models to work with minimal training data or even classify previously unseen object categories. These approaches reduce annotation requirements and enable faster deployment for new use cases.
Real time processing advances
Hardware improvements and algorithmic optimizations continue pushing the boundaries of real time semantic segmentation. Edge computing devices now support sophisticated segmentation models, enabling new applications in mobile and embedded systems.
Multi modal integration
Future semantic segmentation systems will likely integrate multiple data sources beyond visual imagery, incorporating depth information, thermal data, and other sensor inputs for more comprehensive scene understanding.
FAQs about What is Semantic Segmentation
1. What future trends should businesses be aware of in semantic segmentation?
Several key trends are shaping the future of semantic segmentation for businesses:
- Transformer based architectures: These models improve accuracy by better capturing global context and complex patterns, outperforming traditional convolutional networks, especially on challenging datasets.
- Few shot and zero shot learning: These techniques reduce the need for large annotated datasets by enabling models to learn from very limited examples or even recognize unseen categories, which cuts down annotation costs and accelerates new use case deployment.
- Real time processing: Advances in hardware and algorithms now allow semantic segmentation to run efficiently on edge devices, supporting fast inference for applications requiring immediate results, such as mobile and embedded systems.
- Multi modal integration: Combining visual data with other sensor inputs like depth or thermal information enhances the model’s ability to understand complex scenes, making segmentation more reliable in industrial, automotive, and security contexts.
2. How can businesses reduce the cost and time of semantic segmentation projects?
By leveraging pre-trained models, adopting few shot learning techniques, and outsourcing high quality data annotation, companies can significantly lower both development time and operational costs.
3. Who offers the best image annotation tools and services for semantic segmentation projects?
For in-house teams, platforms such as Labelbox, Supervisely, and CVAT provide powerful tools with advanced annotation features.
For businesses seeking end-to-end solutions, professional service providers such as LTS GDS deliver scalable, high quality annotation services tailored to complex segmentation needs – ideal for accelerating time to market and ensuring data accuracy.
Getting Started with Semantic Segmentation
Organizations considering semantic segmentation implementation should begin with a clear understanding of their objectives and constraints.
Define use case
Start by clearly articulating the business problem you’re trying to solve and how semantic segmentation can address it. Consider factors like required accuracy levels, processing speed requirements, and integration needs.
Assess data assets
Evaluate your available data and determine what additional annotation or collection efforts may be required. High quality training data remains the most critical success factor for semantic segmentation projects.
Plan implementation strategy
Develop a phased approach that allows for iterative improvement and learning. Starting with a focused pilot project helps validate approaches before scaling to full production systems.
Partner with experienced providers
Consider working with experienced providers who can guide you through the implementation process and help avoid common pitfalls. The complexity of semantic segmentation projects makes professional support valuable for most organizations.
LTS GDS stands as a premier provider of high-precision semantic segmentation services. Our unwavering commitment to exceptional accuracy (consistently 98-99%), validated by rigorous multi-stage review processes and DEKRA certification, ensures that your machine learning models are built on a foundation of superior data. We possess deep expertise in handling complex semantic segmentation projects across diverse and demanding industries, including automotive, retail analytics, and industrial safety.
For businesses seeking professional support for their computer vision initiatives, our teams at LTS GDS offer comprehensive services from initial consultation through full scale implementation.
Learn more about our image annotation services and discover how we can support your semantic segmentation projects!



