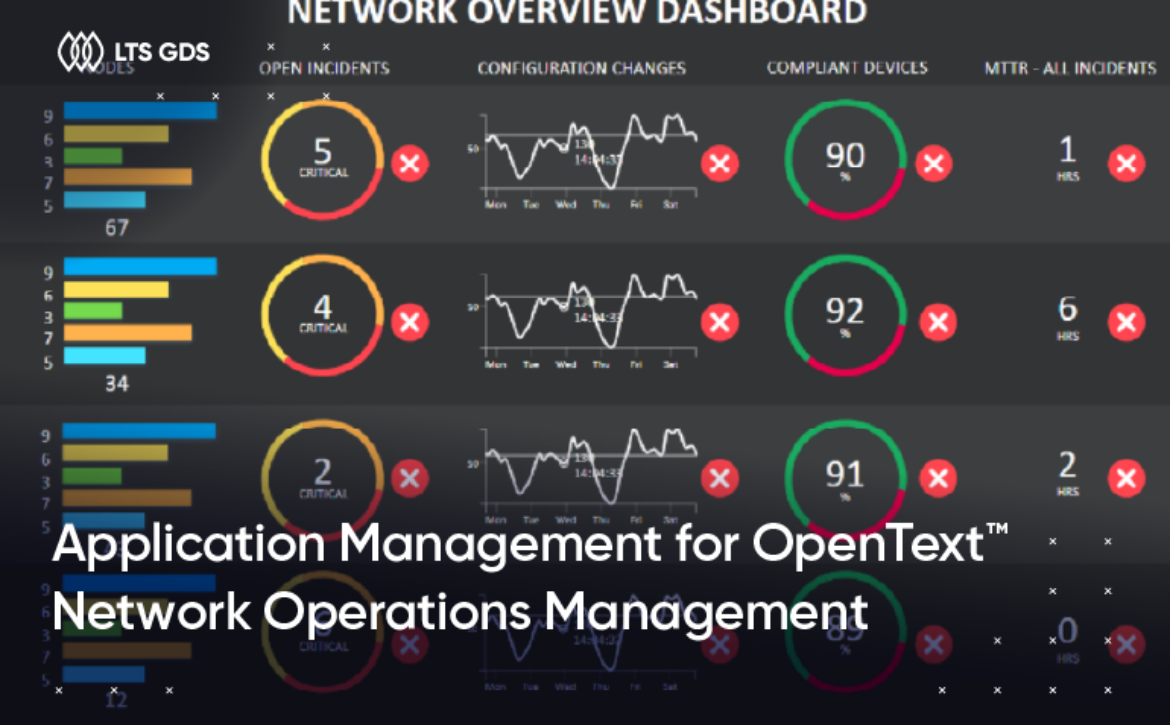
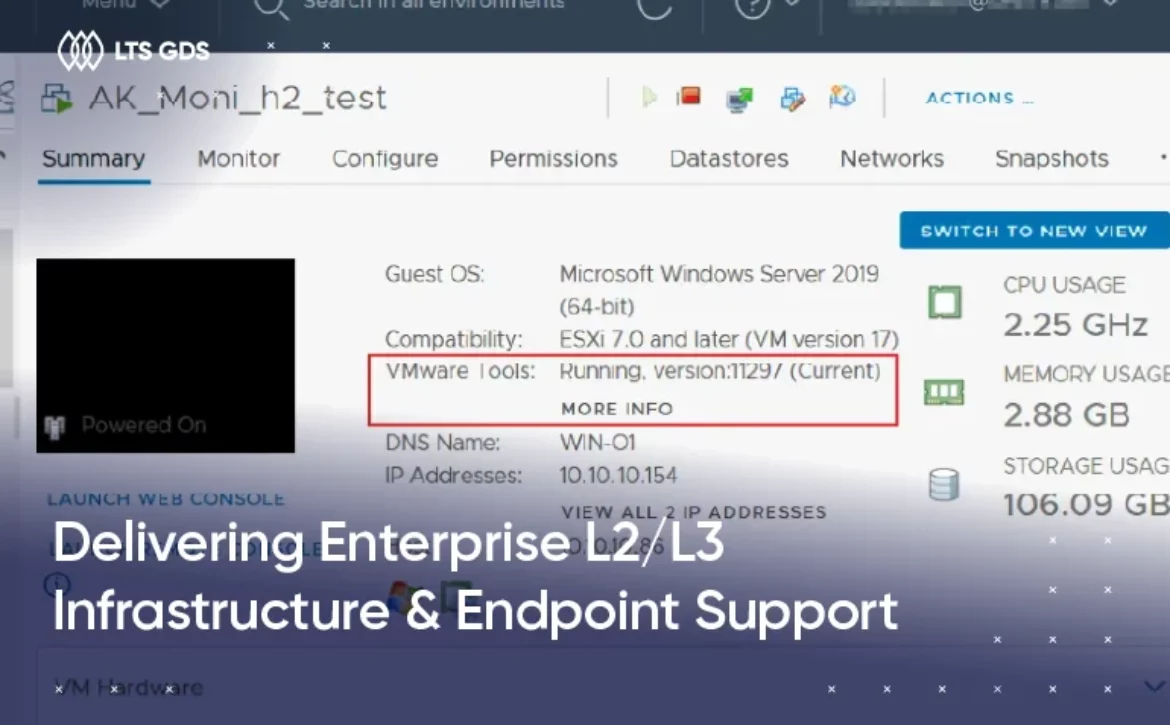
Client overview
Our client is a leading manufacturing service provider in Japan, operating across multiple distributed locations. Their IT environment supports thousands of endpoint devices and a mix of Windows, Linux, and UNIX servers. They operate in a heavily regulated environment, where system availability, data protection, and audit readiness are mandatory.
Before cooperating with us, the client faced some operational challenges:
– Limited internal resources to operate infrastructure 24/7.
– A complex and aging infrastructure combining on-premises and virtualized systems.
– Increasing endpoint security threats with slow investigation and response.
– Insufficient in-house capacity to handle escalations and root-cause analysis.
What the client needs
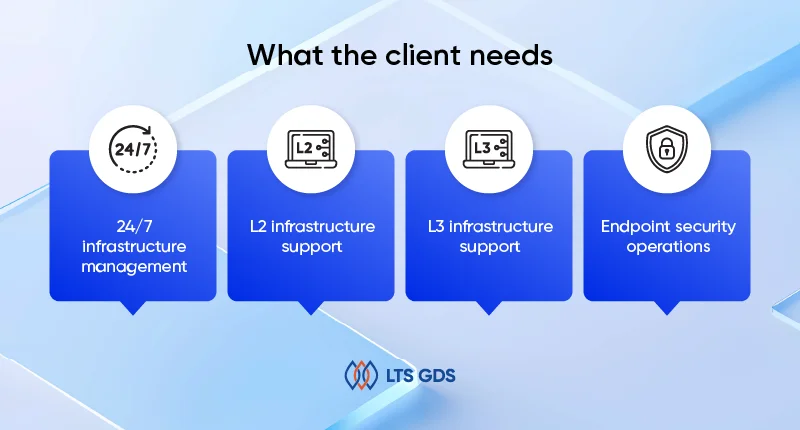
The client’s goal was to stabilize their IT operations 24/7. Specifically, they requested:
24/7 infrastructure management
Continuous monitoring and support to maintain uptime across servers, virtualization platforms, and network components.
L2 infrastructure support
– OS-level operations across Windows, Linux, and UNIX
– Patch management and scheduled changes
– Incident handling and recovery actions
– Routine operational tasks with clear documentation
L3 infrastructure support
– Technical troubleshooting for Hyper-V and VMware vSphere
– Advanced support for RDS, storage, backup, and network performance
– Escalation handling and long-term fix recommendations
Endpoint security operations
Rapid detection, investigation, and response to endpoint threats across thousands of devices.
How we did it

To meet the client’s requirements, we followed a structured delivery process designed to ensure a smooth transition, stable operations, and continuous service improvement. The process covered discovery, knowledge transfer, daily operations, system maintenance, and ongoing reporting.
1. Discover the client’s needs
LTS GDS started by gaining a clear understanding of the client’s infrastructure environment and operational challenges.
– Analyzed the client’s requirements for 24/7 infrastructure management and endpoint security
– Reviewed system complexity, incident history, and performance issues across Windows, Linux, and UNIX servers
– Assessed the virtualization environment, including Hyper-V and VMware vSphere
– Identified risks related to backup, storage, network performance, and endpoint threats
Based on this analysis, we built a customized service proposal that clearly defined L2 and L3 responsibilities, coverage scope, and escalation paths. We also defined Service Level Agreements aligned with the client’s business and compliance needs before finalizing and signing the contract.
2. Transfer the knowledge
To execute smoothly, we focused on knowledge transfer before officially operating.
– Collected and reviewed existing documentation, system configurations, and infrastructure architecture
– Understood current operational workflows, dependencies, and known issues
– Prepared internal teams and aligned tools with the client’s environment
– Established the final operating model, including shift schedules and escalation rules
– Ran trial operations to validate processes, response times, and communication flows
3. Operate the system
After the handover, our dedicated 10-member team began full-scale operations under a 24/7 coverage model.
– Monitored systems and infrastructure using Nagios and Elastic Stack
– Processed incoming incidents, service requests, and change requests according to defined SLAs
– L2 engineers handled daily OS-level tasks, patching, recovery actions, and first-line incident response
– L3 engineers handled escalations, including complex troubleshooting for Hyper-V, VMware vSphere, RDS, network performance, storage, and backup
– Endpoint security alerts were monitored and investigated using Trellix ENS, ePO, Global Threat Intelligence, and EDR
Performance metrics and service KPIs were tracked to ensure consistent service delivery.
4. Maintain and update
To keep operations stable and scalable, we maintained accurate documentation and updated operational knowledge.
– Documented solutions for incidents, changes, and recurring operational tasks
– Updated internal and client-facing knowledge bases on a regular basis
– Consolidated configurations, procedures, and technical data into centralized systems
– Conducted periodic reviews to ensure documentation remained relevant and accurate
This approach reduced repeat incidents and improved resolution time for similar issues.
5. Report and improve
Finally, we ensured transparency and improvement through structured reporting and regular reviews.
– Provided regular service and performance reports
– Held review meetings with the client to discuss service quality, incident trends, and feedback
– Recommended infrastructure improvements, optimizations, and preventive actions
– Adjusted SLAs and service scope as the client’s business and operational needs evolved
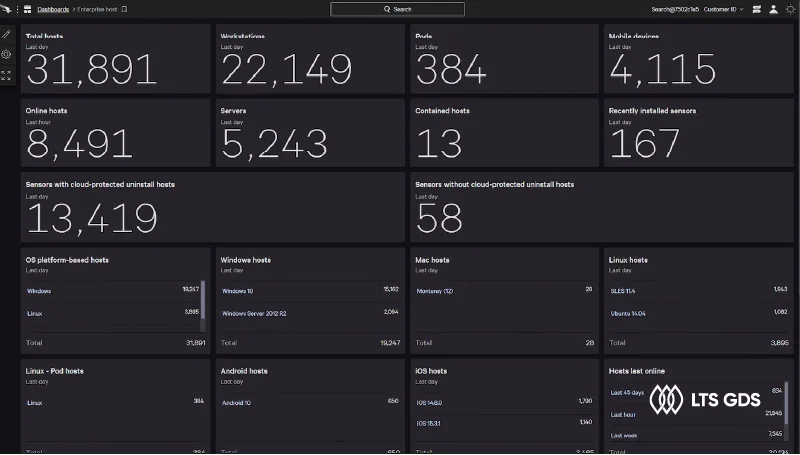
What the results have

Over the 24-month execution, the project achieved:
– 26,000+ support calls and tickets handled
– Stable performance across Windows and Linux servers
– Consistent SLA compliance, with response times maintained at:
- Critical: ≤ 1 hour
- High: ≤ 2 hours
- Medium & Low: ≤ 4 hours
– Faster incident response and resolution
– Improved endpoint threat detection and containment
– Reduced pressure on the client’s internal IT team
– Improved compliance readiness and audit confidence