



Multimodal AI: Unlocking New Dimensions of Intelligent Automation in 2025
The rapid growth of artificial intelligence has brought about a new generation of systems that can process and interpret information in ways that more closely resemble human reasoning. This breakthrough, known as multimodal AI, is rapidly transforming how enterprises harness data to drive automation, decision-making, and innovation.
Market analysis forecasts a surge in multimodal AI adoption across industries such as healthcare, automotive, finance, and software development, where the complexity and variety of data demand more sophisticated AI capabilities. However, developing and deploying multimodal AI solutions requires overcoming significant challenges, including the need for high-quality, precisely annotated datasets spanning multiple modalities and domains.
At LTS GDS, we combine deep expertise in data annotation, including specialized labeling for fine-tuning coding large language models (LLMs), with end-to-end software development services. This integrated approach helps enterprises accelerate multimodal AI projects, reduce vendor complexity, and ensure superior model performance.
In this article, we will unpack the core technologies behind multimodal AI, explore its strategic value for IT outsourcing, and highlight how LTS GDS’s comprehensive annotation and development capabilities empower organizations to capitalize on this next frontier of AI innovation.
Let’s dive in!
What is Multimodal AI?
Multimodal AI refers to AI systems capable of processing and integrating information from multiple modalities or types of data. These modalities can include text, images, audio, video or other forms of sensory input. Unlike traditional unimodal systems that excel at single-task processing, multimodal AI creates a comprehensive understanding by synthesizing information from various sources simultaneously.
Think of multimodal AI as the digital equivalent of human perception. When humans interact with the world, they don’t rely solely on sight or sound, they combine visual cues, auditory information, textual context, and even spatial awareness to form complete understanding. Similarly, multimodal AI systems integrate diverse data streams to generate more accurate, contextually relevant insights.
The fundamental distinction lies in the system’s ability to cross-reference and correlate information across different data types. For instance, a multimodal AI system analyzing customer feedback might simultaneously process written reviews, social media images, video testimonials, and audio recordings to provide an integral understanding of customer sentiment – something impossible with single-mode systems.
At its core, multimodal AI is about combining different types of data to create a more comprehensive understanding of the world. This comprehensive approach enables AI systems to tackle complex, real-world problems that require nuanced understanding and contextual awareness.
How Multimodal AI Works: Technologies & Core Components
As discussed, multimodal AI is built on the ability to process, integrate, and reason over multiple types of data, such as text, images, audio, video, and code, within a unified intelligent system. This capability is enabled by a combination of advanced machine learning techniques, robust data annotation processes, and flexible model architectures.
Below, we break down the key technological pillars and operational components that power modern multimodal AI.
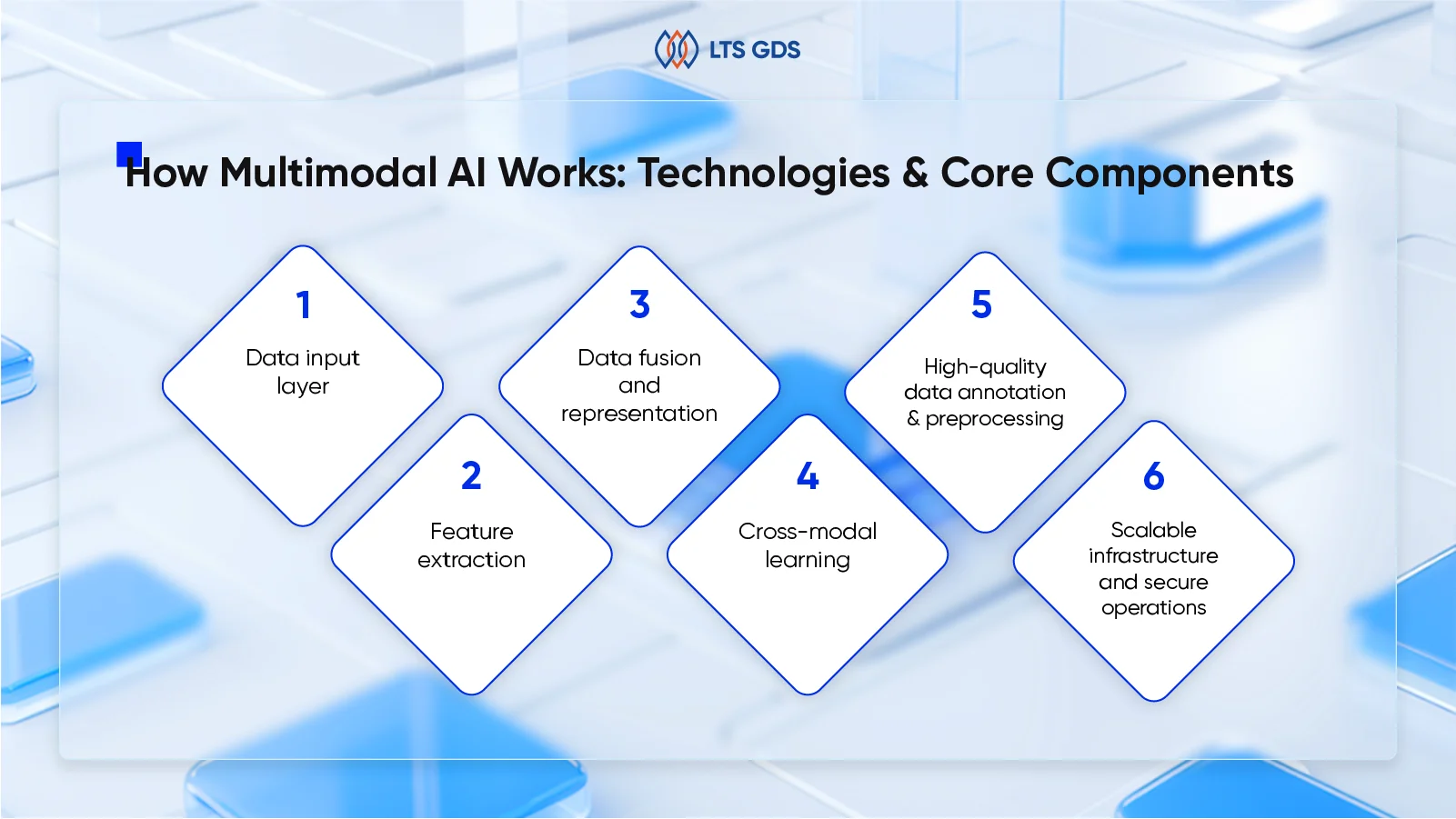
Data input layer
The foundation of any multimodal AI system begins with its data input layer, which must accommodate various data types simultaneously. This layer employs specialized encoders for different modalities:
- Text encoders: Process natural language using transformer architectures and attention mechanisms
- Image encoders: Utilize convolutional neural networks (CNNs) or vision transformers to extract visual features
- Audio encoders: Transform sound waves into meaningful representations using spectral analysis
- Video encoders: Combine temporal and spatial processing to understand motion and context
Feature extraction
Once data enters the system, specialized encoders or neural networks are applied to each modality to extract meaningful features. For example, convolutional neural networks (CNNs) for images, transformers for text, and spectrogram-based models for audio.
Data fusion and representation
Once features are extracted, multimodal AI employs fusion strategies to integrate them:
- Early fusion:
Raw data from different modalities (e.g., text and image pixels) are combined before feature extraction. This approach allows the model to learn joint representations from the outset, capturing low-level correlations between modalities. - Late fusion:
Each modality is processed independently through dedicated models or neural network branches. The outputs (features or predictions) are then merged at a later stage, often through concatenation or weighted averaging. This method is effective when modalities have distinct characteristics or noise profiles. - Attention-based fusion:
Leveraging attention mechanisms, the model dynamically weighs the importance of each modality depending on the context of the input or task. This enables more flexible and context-aware integration, especially in complex scenarios where certain modalities may be more informative than others.
Cross-modal learning
- Knowledge transfer:
Multimodal models can transfer insights gained from one modality to enhance understanding in another.
For example, textual descriptions can help disambiguate objects in images, or visual cues can clarify ambiguous spoken commands.
- Alignment techniques:
Methods such as contrastive learning and co-attention align features across modalities, ensuring that the model can relate and synchronize information even when data is asynchronous or partially missing.
Generative multimodal models
- Transformer architectures:
Modern multimodal AI relies heavily on transformer-based models, which can process sequences of tokens from different modalities and learn complex relationships between them. These architectures are foundational for tasks like generating code from natural language prompts, creating images from text, or synthesizing video from scripts. - Diffusion models and multimodal LLMs:
Recent advances include diffusion models for image and video generation, and large language models (LLMs) fine-tuned to handle code, text, and dialogue together. These models require extensive, high-quality multimodal datasets for training.
High-quality data annotation & preprocessing
- Comprehensive annotation:
Multimodal AI models depend on precisely labeled datasets spanning all relevant modalities. This includes semantic segmentation, instance segmentation, video annotation, 3D image annotation, and increasingly, code labeling for fine-tuning coding LLMs. - Specialized data labeling for coding LLMs:
For AI models that generate or evaluate code, annotation involves not just labeling code snippets, but also crafting and verifying prompts, answers, dialogues, and code evaluations. This process ensures logical coherence, code quality, and alignment with real-world programming standards.
LTS GDS, for example, provides end-to-end support for data labeling in the code domain, including prompt generation, answer creation, dialogue evaluation, and code review that is critical for building trustworthy, domain-specific coding LLMs.
Scalable infrastructure and secure operations
- Cloud-based training pipelines:
Handling multimodal data at scale requires robust infrastructure, often leveraging cloud-based platforms for distributed training and storage. - Security & compliance:
Given the sensitivity and diversity of data involved, secure data handling, legal confidentiality, and continuous quality assurance are essential to maintain trust and meet regulatory requirements.
Summary: Core components of multimodal AI
| Component | Description | Example applications |
| Data fusion (Early/Late/Attention) | Integrates multi-source data into unified representations | Image captioning, video Q&A |
| Cross-modal learning | Transfers knowledge and aligns features across modalities | Visual question answering, speech-to-text |
| Generative multimodal models | Produces content across modalities using transformer/diffusion architectures | Code generation, text-to-image |
| High-quality data annotation | Ensures datasets are accurately labeled for each modality, including code and dialogue | LLM fine-tuning, autonomous driving |
| Scalable infrastructure & security | Provides the computational backbone and secure environment for model development and training | Cloud AI pipelines, secure annotation |
Popular Multimodal AI Models Examples
Below is a detailed overview of some of the most influential multimodal AI models driving innovation across industries.
| Model name | Developer | Key modalities | Parameters | Notable features | Use cases |
| GPT-Fusion | OpenAI | Text, Image, Audio, Video | ~1.5 trillion | Cross-modal translation, contextual deep learning, adaptive intelligence | Multimedia content creation, scientific research, complex problem-solving |
| Nexus-AI | Google DeepMind | Visual, Auditory, Tactile | ~750 billion | Sensory fusion, contextual reasoning, adaptive learning | Autonomous robotics, medical diagnostics, AR/VR |
| Gemma 3 | Google DeepMind | Vision-language (Images, Text) | 4B, 12B, 27B | Dynamic segmentation for high-res images, supports 140+ languages, reinforcement learning optimized | Image analysis, visual Q&A, object recognition |
| Qwen 2.5 VL | Alibaba Cloud | Visual and Text | 7B, 72B | Vision transformer integrated with language model, excels in VQA, image captioning, content moderation | Visual question answering, scene interpretation |
| GPT-4o | OpenAI | Text, Image, Audio | Not publicly disclosed | Handles multimodal inputs with advanced reasoning and generation | Conversational AI, multimodal interaction |
| Gemini Ultra | Google DeepMind | Multi-dimensional data | Not publicly disclosed | Quantum-enhanced processing, ethical AI framework, contextual deep learning | Scientific research, medical diagnostics, robotics |
| Claude 3 | Anthropic | Text, Image | Not publicly disclosed | Multimodal understanding with emphasis on safety and ethics | Conversational AI, content generation |
Why Multimodal is a Strategic Asset for Your Organization

Deeper understanding and smarter decision-making
Unlike traditional AI models that process only one type of data at a time, multimodal AI simultaneously analyzes text, images, audio, video, and even code. This holistic data integration enables your systems to gain a richer, more nuanced understanding of complex situations, leading to more accurate insights and smarter decisions.
For example, in customer service, AI can interpret a customer’s voice tone, facial expression, and chat messages together to provide highly personalized responses.
Enhanced customer experience and personalization
By interpreting multiple data sources in context, multimodal AI delivers more natural and engaging interactions. This means your organization can offer personalized services that respond not just to words, but also to visual cues and emotional signals, creating superior user experiences that boost satisfaction and loyalty.
Accelerated innovation and operational efficiency
Multimodal AI automates complex workflows that involve diverse data formats, reducing manual effort and human error. This leads to faster processing times and lower operational costs.
Industries like healthcare benefit from quicker, more accurate diagnostics by combining medical images, patient records, and doctor’s notes. Similarly, marketing teams can analyze social media posts, customer reviews, and videos simultaneously to optimize campaigns.
Competitive advantage through early adoption
Organizations that embrace multimodal AI early gain a significant edge in digital transformation. The ability to understand and act on richer data sets enables faster innovation cycles and more agile responses to market changes. This advantage is critical in sectors where speed and precision determine market leadership.
Scalability and flexibility across industries
Multimodal AI’s adaptable architecture supports a wide range of applications – from autonomous vehicles integrating sensor data to educational platforms combining text, video, and interactive content. This flexibility allows your organization to scale AI initiatives across departments and use cases, maximizing ROI.
Improved data security and compliance
As AI systems process increasingly sensitive multimodal data, robust security and governance become vital. Multimodal AI solutions can be designed with privacy-preserving techniques and compliance frameworks to protect your data assets and build stakeholder trust.
Multimodal AI Risks & How Can Organizations Mitigate These Risks
Data quality and consistency challenges
Multimodal AI systems are only as effective as the data they process. Ensuring consistent quality across diverse data types poses significant challenges, especially when handling varied sources and formats.
Mitigation strategy: Organizations must adopt robust data annotation strategies to maintain data integrity. This involves establishing comprehensive data governance frameworks with clear quality standards, regular audits, and automated quality checks spanning all modalities.
Computational complexity and resource demands
Processing multiple data modalities simultaneously demands substantial computational power. This complexity often results in higher infrastructure costs and longer processing times, potentially affecting system performance and scalability.
Mitigation strategy: Investing in cloud-based, scalable solutions that adjust dynamically to workload demands is essential. A phased deployment, starting with simpler integrations and gradually increasing complexity as expertise and infrastructure grow, helps manage resources efficiently.
Integration and technical challenges
Seamlessly combining different AI models across modalities is technically demanding. Poorly architected systems risk bottlenecks and suboptimal performance.
Mitigation strategy: Employ a phased implementation approach with thorough testing and optimization at each stage. Collaborating with specialized partners can help navigate these complexities, minimizing risks and maximizing the benefits of multimodal AI.
Privacy and security vulnerabilities
Handling sensitive information across multiple data types increases privacy and security risks. Protecting against breaches and unauthorized access is critical.
Mitigation strategy: Implement multi-layered security frameworks tailored to each data modality’s vulnerabilities. This includes encryption, strict access controls, regular security audits, and compliance with data protection regulations.
Bias and fairness concerns
Multimodal AI’s complexity can amplify biases present in training data, risking unfair or discriminatory outcomes across modalities.
Mitigation strategy: Develop comprehensive bias detection and mitigation protocols throughout the AI lifecycle. Use diverse datasets, conduct regular bias audits, and apply fairness metrics to ensure equitable performance across demographics and data types.
Interpretability and explainability issues
As multimodal AI integrates more data types, understanding how decisions are made becomes harder. This lack of transparency poses challenges in regulated industries requiring explainable AI.
Mitigation strategy: Invest in explainable AI tools and methodologies that clarify decision processes. Continuous monitoring and audit trails help track performance and identify anomalies, ensuring accountability.
Skills gap and expertise requirements
Multimodal AI demands specialized skills that many organizations may lack, creating hurdles in implementation and ongoing maintenance.
Mitigation strategy: Prioritize comprehensive training programs covering technical multimodal AI competencies, ethical AI practices, and industry-specific knowledge. Partnering with experts and specialized providers accelerates capability building.
LTS GDS offers tailored data annotation and AI training services designed to help organizations bridge this skills gap effectively, ensuring smoother multimodal AI adoption and sustained success.
Real-World Appliances of Multimodal AI
Multimodal AI is transforming industries by integrating and analyzing diverse data types (such as text, images, audio, and video) to deliver smarter, more context-aware solutions. Here are key use cases across major sectors:

Customer service
Multimodal AI enhances customer interactions by analyzing voice tone, facial expressions, and text simultaneously. This enables personalized, empathetic responses that improve satisfaction and reduce resolution times. For example, conversational AI platforms use multimodal inputs to better understand and address customer needs.
Healthcare
In healthcare, multimodal AI combines medical images, patient records, and clinical notes to improve diagnostics and treatment recommendations. It accelerates research by interpreting complex data like lab reports, diagrams, and trial results, helping bring innovations to market faster.
Retail and eCommerce
Retailers use multimodal AI to analyze customer behavior, product images, and reviews, enabling personalized recommendations and optimized shopping experiences. Features like image-based product search and style suggestions enhance engagement and boost sales.
Autonomous vehicles
Self-driving cars rely on multimodal AI to fuse data from cameras, lidar, radar, and GPS for accurate environment perception and decision-making. This integration improves obstacle detection, navigation, and safety in real time.
Security and surveillance
Security systems apply multimodal AI to analyze video footage alongside audio signals, detecting unusual behavior or threats more effectively. This leads to faster, more accurate incident responses.
Manufacturing and predictive maintenance
By combining sensor data, visual inspections, and operational logs, multimodal AI predicts equipment failures and schedules maintenance proactively, reducing downtime and increasing productivity.
Education and accessibility
Multimodal AI supports inclusive learning by converting speech to text, describing images for visually impaired users, and enabling interactive, multimodal educational content that adapts to diverse learning styles.
Research and development
Multimodal AI accelerates R&D by interpreting scientific papers, diagrams, tables, and experimental data together, enabling faster insights and innovation across biotech, engineering, and pharmaceuticals.
Future of Multimodal AI
Unified model architectures
The multimodal AI landscape continues evolving rapidly, with emerging trends reshaping what’s possible for enterprise applications. Unified model architectures are becoming increasingly sophisticated, enabling single systems to handle diverse data types without requiring separate processing pipelines for each modality. This evolution simplifies deployment while improving performance and reducing resource requirements.
Real-time processing advancements
Real-time processing capabilities are advancing rapidly, enabling multimodal AI applications in time-critical scenarios such as autonomous systems, live customer service, and immediate fraud detection. These improvements open new application areas that were previously impractical due to latency constraints.
Democratization through improved tools
The democratization of multimodal AI through improved tools and platforms is making these capabilities accessible to organizations without extensive AI expertise. Open-source frameworks and cloud-based services are reducing barriers to entry while enabling rapid prototyping and deployment of multimodal solutions.
Synthetic data generation
Synthetic data generation for multimodal training is becoming increasingly sophisticated, addressing one of the primary challenges in developing robust multimodal systems. Advanced simulation techniques can generate coordinated datasets across multiple modalities, reducing dependence on expensive real-world data collection while maintaining training effectiveness.
FAQ about Multimodal AI
1. What is an example of multimodal AI?
Multimodal AI refers to systems that can process and integrate multiple types of data (such as text, images, audio, video, and even code) within a single model. Some prominent real-world examples include:
- Google Gemini: Can receive a photo (e.g., a plate of cookies) and generate a written recipe in response, or vice versa. Gemini processes text, images, video, audio, and code, enabling seamless cross-modal reasoning and content generation.
- OpenAI GPT-4o / GPT-4V: Accepts both text and images as input, allowing tasks like describing images, answering questions about pictures, or generating text based on visual cues.
2. What are the benefits of multimodal models and multimodal AI?
They provide richer context, higher accuracy, robust performance despite noisy data, natural user interactions, broad applicability across industries, cost efficiency, and scalability for future needs.
3. What is the difference between generative AI and multimodal AI?
| Aspect | Generative AI | Multimodal AI |
| Definition | AI that creates new content (text, images, etc.) | AI that processes and integrates multiple data types |
| Primary function | Generate content similar to training data | Understand/generate responses from varied inputs |
| Data input | Typically single-type (e.g., text-only) | Multiple types (text, images, audio, etc.) |
| Output | New data/content of the same type | Can generate or interpret across modalities |
| Example | DALL-E generates images from text prompts | Gemini answers questions about images and text |
Generative AI focuses on creating new content from learned data, usually within a single modality (e.g., generating text or images).
Multimodal AI can process, combine, and generate outputs from multiple data types, enabling richer, context-aware understanding and generation
How Does LTS GDS Turbocharge Your Enterprise Next AI Projects?
Fine-tuned LLMs: The backbone of intelligent coding systems
As enterprises embrace multimodal AI and intelligent assistants, fine-tuned Large Language Models (LLMs) are fast becoming the backbone of modern AI systems, especially for code-related tasks. These models power smart developer tools, code generation assistants, and AI copilots.
To achieve high performance, they require high-quality, domain-specific training data. That’s where LTS Global Digital Services (LTS GDS) comes in.
Why data labeling matters for multimodal AI in coding
Fine-tuning LLMs for code generation demands more than raw data. It requires carefully curated, logic-driven, and contextually accurate datasets.
LTS GDS provides specialized data labeling for code-focused LLMs, ensuring models can:
- Understand programming syntax and logic
- Generate accurate, bug-free code
- Respond naturally in coding dialogues
- Assist developers in real-world problem-solving contexts
We focus on building Supervised Fine-tuning (SFT) datasets that help AI learn coding tasks effectively, enabling enterprise AI systems to deliver reliable, human-like output.
LTS GDS’s end-to-end data labeling capabilities
Our comprehensive services support every aspect of AI coding assistant training:
- Answer generation
- Crafting natural, unbiased, and precise responses based on prompts
- Optimized for clarity and code correctness
- Prompt + answer creation
- Generating high-quality Q&A pairs
- Adding related or expanded question variants
- Prompt + answer verification
- Reviewing AI-generated answers for logic, structure, and code quality
- Ensuring responses align with programming standards
- Dialogue generation & review
- Creating multi-turn, human-like dialogues for support systems
- Refining tone, grammar, and context
- Coding evaluation
- Assessing full code outputs, including instruction, plan, and implementation
- Ensuring completeness and accuracy across multiple programming languages
What makes LTS GDS a trusted partner in enterprise AI
LTS GDS combines human expertise, technical depth, and secure workflows to deliver enterprise-grade AI support:
✅ 100+ expert data annotators trained in programming and machine learning
✅ 20+ domain experts across Python, Java, C#, Bash, Scala, and more
✅ Acceptance rates >90% in recent code generation and verification projects
✅ Expertise in NLP, ML, computer vision, speech, and generative AI
✅ End-to-end project workflow: requirement analysis → pilot task → team setup → QA + iteration → scale
✅ Enterprise-grade security with NDAs, VPNs, physical access control, and data loss prevention systems
Whether your team is developing multimodal assistants that combine code with natural language, or building next-gen tools for developer productivity, LTS GDS helps fine-tune your enterprise AI models with precision, scale, and confidence.
Ready to Fine-Tune Smarter AI Systems?
Partner with LTS GDS to supercharge your AI products with data-driven results. Let us help your team:
- Accelerate AI model readiness
- Improve response accuracy and naturalness
- Reduce development cycles
- Scale coding assistant performance
Explore our solutions for multimodal AI, fine-tuned LLMs, and code generation use cases.
Contact GDS for a free pilot for your enterprise AI project.



