



The AI landscape has shifted dramatically over the past two years. We’ve moved from models that understand only text or only images to systems that can seamlessly process video, interpret audio, read charts, and respond with contextual understanding across multiple formats simultaneously. This evolution demands a fundamental change in how we prepare training data.
Multimodal data labeling has become the backbone of next-generation AI systems. As organizations race to build and deploy multimodal AI models, from chatbots that understand images to autonomous systems that process sensor data, the quality of their training data directly decides their competitive advantage. Yet many teams still approach multimodal annotation with single-modal strategies, leading to inconsistent results.
This guide breaks down what multimodal data labeling actually entails, why it’s critical for modern LLMs and generative AI, and how to implement it effectively at scale.
Introduction to Multimodal Data
Multimodal data labeling refers to the process of annotating datasets that contain multiple data types such as text paired with images, video combined with audio transcripts, or sensor data synchronized with visual information. Unlike traditional single-modal annotation where you might label images or transcribe audio separately, multimodal data annotation requires understanding the relationships and context across different data formats.
Examples of multimodal models
The current generation of AI systems demonstrates the power of multimodal learning:
GPT-4V (Vision) processes both text and images, allowing users to upload photos and ask questions about them. The model can analyze charts, explain memes, or identify objects in images while maintaining conversational context.
Google’s Gemini was built from the ground up as a multimodal system. It handles text, code, audio, images, and video simultaneously, making it capable of tasks like generating code from a whiteboard sketch or answering questions about video content.
Meta’s ImageBind takes multimodality further by learning joint embeddings across six modalities: images, text, audio, depth, thermal, and inertial measurement units (IMU). This allows the model to connect concepts across modalities it wasn’t explicitly trained to pair.
Learn more: Multimodal AI: From Fundamentals to Real-World Applications
Types of data modalities
Multimodal AI models typically work with combinations of these core data types:
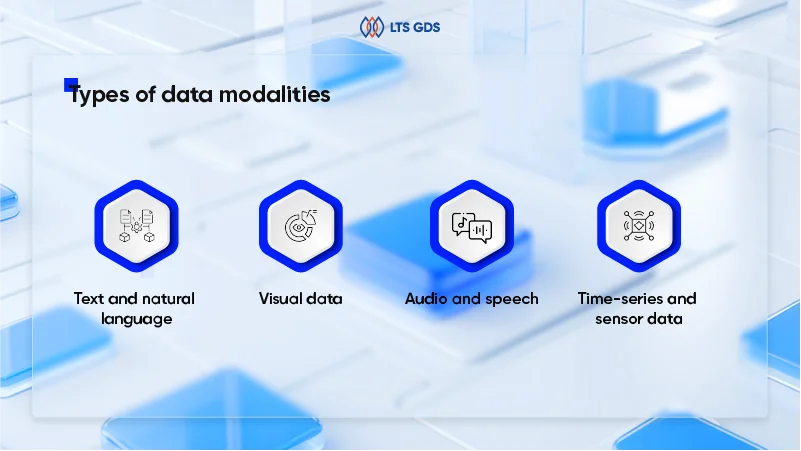
Text and natural language: Written content, transcripts, captions, descriptions, and any language-based data. This remains the foundation for most multimodal systems but now serves as one component rather than the sole input.
Visual data: Images, video frames, medical scans, satellite imagery, and any visual information.
Audio and speech: Voice recordings, environmental sounds, music, and acoustic data. Audio labeling includes transcription, speaker identification, emotion detection, and sound event classification.
Time-series and sensor data: Data from IoT devices, wearables, autonomous vehicles, and industrial sensors. This includes accelerometer readings, GPS coordinates, temperature sensors, and other continuous measurement streams.
How it differs from single-modal data labeling
While single-modal data labeling focuses on one type of input at a time, multimodal data annotation requires synchronization, contextual alignment, and deeper cross-modal reasoning. The table below highlights the core differences:
| Single-modal data labeling | Multimodal data labeling | |
| Data input | Works with a single type of data (e.g., text, images, or audio). | Involves multiple data streams such as text, video, audio, images, LiDAR, or radar. |
| Application scope | Effective for narrow tasks like image classification, sentiment analysis, or speech-to-text. | Enables complex scenarios like self-driving cars, medical diagnostics, fraud detection, and video-based Q&A. |
| Labeling requirements | Defined success criteria within one modality. | Requires temporal synchronization, cross-modal consistency, and an understanding of how modalities reinforce or contradict each other. |
Why Multimodal Data Labeling Matters for LLMs and Generative AI
Large language models have reached impressive capabilities with text alone, but real-world applications demand more. Users don’t communicate in pure text. They share screenshots of error messages, send photos of products, upload documents with complex layouts, and expect AI to understand context that spans multiple formats.
Multimodal LLM training data teaches models to bridge the semantic gap between modalities. When a model learns from properly labeled pairs of images and detailed descriptions, it builds internal representations that connect visual features to language concepts. This enables the model to generate accurate descriptions of new images, answer questions about visual content, or even create images from text descriptions.
For generative AI, multimodal data annotation directly shapes output quality. If you’re building a model that generates product descriptions from images, the quality of your image-text pair annotations determines whether the model learns to identify key product features and describe them accurately, or whether it learns superficial correlations that break down on edge cases.
The business implications are substantial. Organizations with high-quality multimodal training data can:
Deploy more capable AI products that handle the full spectrum of user inputs rather than forcing users into constrained interaction patterns.
Reduce deployment failures caused by models encountering modality combinations they weren’t properly trained to handle.
Accelerate time-to-market by building on solid training foundations rather than iterating endlessly to fix data quality issues discovered after deployment.
Differentiate in crowded markets where everyone has access to similar base models, but data quality determines real-world performance.
Read more: A Guide to Data Labeling for Fine-tuning LLMs
Key Types of Multimodal Data Labeling
Different AI applications require different combinations of modalities and annotation approaches. Understanding these categories helps teams plan resource allocation and select appropriate annotation services.

Image-text pairs
This pairing forms the foundation of vision-language models. Annotators provide detailed captions, descriptions, or textual answers about images. The labeling goes beyond simple descriptions, it requires capturing relationships, context, actions, and relevant details that a model needs to learn visual-semantic connections.
Video-text annotations
Video annotation for multimodal models requires temporal understanding. Annotators might provide time-stamped descriptions of events, identify when specific actions occur, or create summaries that capture the video’s narrative arc. This training data teaches models to understand not just what appears in frames but how events unfold over time.
Video question-answering datasets represent a particularly valuable type of multimodal annotation. Annotators generate or answer questions that require integrating information across multiple moments in the video, forcing models to learn temporal reasoning alongside visual understanding.
Audio-text transcription and annotation
Beyond transcribing words, annotators may mark speaker changes, emotional tone, background sounds, or audio quality issues. For training multimodal LLMs, the text annotations need to capture not just what was said but contextual audio information the model should learn to process.
Cross-modal entity linking
More advanced multimodal annotation involves explicitly linking entities across modalities. In a video with transcript, annotators might mark when specific named entities mentioned in speech correspond to visual appearances. In documents containing charts and text, they establish connections between data visualizations and textual references.
Sensor fusion labeling
For robotics and autonomous systems, multimodal annotation often involves fusing sensor data. Annotators label objects and events that appear simultaneously across camera, LiDAR, and radar inputs, ensuring temporal alignment and consistent identification across sensor types.
Multimodal instruction data
A newer category gaining importance for instruction-tuned LLMs involves creating multimodal instruction-response pairs. Annotators craft diverse instructions that reference multiple modalities along with high-quality responses. This multimodal instruction data teaches models to follow varied user requests across input types, making them more flexible and useful in real applications.
Common Challenges in Multimodal Data Labeling
Organizations scaling multimodal annotation programs consistently face several obstacles that can affect timelines and costs if not addressed proactively.
Complexity of synchronizing different data formats
When annotating video with audio, or sensor data from multiple streams, everything must align precisely. A 50-millisecond mismatch between when an annotator marks an event in video and when they mark the corresponding audio feature can teach the model incorrect associations.
Quality consistency and human bias
Maintaining consistent quality standards across modalities requires annotators who understand how different data types interact. An annotator might excel at image labeling but struggle to capture the nuances needed in paired text descriptions. Or they might write detailed text annotations but miss visual details that create mismatches between modalities.
Human bias manifests differently in multimodal contexts. An annotator’s interpretation of an image might unconsciously influence how they label associated text, or vice versa. Besides, an annotator might suffer from cultural and linguistic biases. For global AI products, this requires diverse annotation teams and careful guideline development.
Scaling large datasets
Multimodal annotation simply takes longer per example than single-modal labeling. Annotators waste time switching between views, loading different file types, or manually ensuring alignment.
Quality assurance for multimodal data labeling requires specialized processes. A reviewer must check not just whether individual modality labels are correct, but whether they’re consistent across modalities.
Finding and training annotators capable of high-quality multimodal work proves harder than many organizations anticipate. The skillset combines domain knowledge with technical precision and attention to detail across multiple dimensions simultaneously.

Best Practices for Effective Multimodal Data Labeling
Organizations that successfully scale multimodal annotation programs share several common practices that separate good intentions from actual execution.
Human-in-the-loop approaches
Pure automation doesn’t work for most multimodal annotation tasks. Human-in-the-loop multimodal labeling shines for handling edge cases and ambiguity. The key is establishing clear guidelines, with well-defined criteria for when examples need human review and what level of annotator expertise each example requires.
Strong QA and validation pipelines
Quality assurance for multimodal data labeling requires a multi-layered approach. Gold standard datasets serve as benchmarks for annotator performance. Create a subset of multimodal examples with ground-truth labels reviewed by multiple experts, then periodically test annotators against these examples to measure accuracy and consistency.
Feedback loops between annotators and ML engineers prove invaluable. When models trained on multimodal data show unexpected behaviors, trace these back to potential annotation issues. Similarly, when annotators need to handle ambiguous cases, route these to ML engineers to clarify how the model will use this data. This dialogue continuously improves both annotation guidelines and model architecture decisions.
The Future of Multimodal Data Labeling
The next phase of multimodal AI development will place even greater demands on data annotation while simultaneously introducing new capabilities that reshape the field.
Foundation models trained on massive multimodal datasets are already reducing the need for task-specific annotation in some domains. As these models improve, organizations will shift from annotating training data from scratch to curating smaller, high-quality datasets for fine-tuning. This changes economics but doesn’t eliminate the need for expert multimodal annotation – if anything, it increases the premium on quality over quantity.
Synthetic data generation for multimodal training is advancing rapidly. Models can now generate realistic image-text pairs, videos with corresponding descriptions, or sensor data that mimics real-world distributions. However, synthetic data carries risks of compounding biases and unrealistic edge cases. The foreseeable future involves hybrid approaches: synthetic data for common cases, with human-annotated multimodal data for edge cases, safety-critical scenarios, and bias mitigation.
Real-time multimodal annotation represents an emerging frontier. Rather than annotating static datasets, systems will incorporate human feedback on live multimodal inputs, allowing models to learn and adapt continuously. This requires new annotation workflows, faster turnaround times, and robust quality controls that work under time pressure.
Regulation will increasingly shape multimodal data labeling practices. As AI systems trained on multimodal data make consequential decisions in healthcare, autonomous vehicles, and other high-stakes domains, regulatory frameworks will mandate documentation of training data provenance, annotator qualifications, bias testing, and quality assurance procedures. Organizations building multimodal AI systems need annotation programs that can meet these emerging requirements.
The gap between organizations with robust multimodal data labeling capabilities and those without will likely determine winners and losers in AI product categories.
FAQ about Multimodal Data Labeling
1. How does multimodal data labeling work?
The process typically involves specialized annotators using platforms designed to handle multiple data types simultaneously. Annotators label each modality while maintaining consistency across them. Quality assurance processes then verify both individual modality accuracy and cross-modal consistency.
2. Why do LLMs need multimodal data labeling?
Modern large language models are expanding beyond text to handle images, audio, video, and other input types. Multimodal training data teaches these models to understand relationships between different data formats, enabling them to answer questions about images, generate descriptions of video content, or process documents containing both text and figures. Without quality multimodal annotation, LLMs can’t learn these cross-modal connections effectively.
3. What’s the difference between multimodal data annotation and traditional data labeling?
Traditional data labeling focuses on single data types in isolation – labeling images or transcribing audio separately. Multimodal data annotation requires understanding how different data types relate to each other within the same training example. This adds complexity around temporal synchronization, cross-modal consistency, and understanding context that spans multiple input formats.
4. Can multimodal data labeling be automated?
Partial automation is possible, but full automation doesn’t yet match human quality for most complex multimodal tasks. Hybrid approaches work best: automated models generate initial annotations that humans verify and refine. This human-in-the-loop approach balances efficiency with the quality needed for training robust multimodal AI systems.
Shaping the Future of LLMs with Multimodal Data Annotation
Multimodal data labeling has evolved from an emerging challenge to a fundamental requirement for competitive AI development. As models grow more sophisticated and user expectations expand, the quality of multimodal training data directly determines what AI systems can understand and accomplish.
The organizations that will lead in multimodal AI aren’t necessarily those with the largest datasets or the most computing power. They’re the ones who recognize that high-quality, properly annotated multimodal data creates a sustainable competitive advantage.
Ready to build multimodal AI systems on a foundation of high-quality training data?
Our multimodal annotation services combine experienced annotators, purpose-built platforms, and strict quality assurance to deliver the datasets your models need. Let’s discuss how we can support your multimodal AI initiatives with annotation expertise that matches your technical requirements.



