



Large language models have moved from novelty to infrastructure faster than most enterprise technologies in recent memory. In less than three years, LLMs have gone from powering chat demos to sitting at the core of customer support platforms, developer copilots, enterprise search, medical documentation, financial analysis, and internal decision-support systems.
That speed has created a gap. While model capabilities have advanced rapidly, the mechanisms to control, validate, and govern those capabilities have often lagged behind. Teams discover this gap the hard way: a chatbot confidently invents policies, a copilot leaks sensitive data, or an AI agent executes actions no one anticipated.
This is a reason why we need to use LLM guardrails. Guardrails are not a nice-to-have layer added after deployment. They are the operational backbone that makes LLMs usable in high-stakes environments. Without them, even the most capable model becomes unpredictable, fragile, and risky.
This guide examines what guardrails actually are, why they’re essential, and how to implement them effectively across your AI infrastructure.
What are LLM Guardrails?
LLM guardrails are mechanisms that constrain, validate, and guide the behavior of large language models to ensure their outputs are safe, reliable, and aligned with intended use cases.
In practice, LLM guardrails sit around and alongside the model, shaping how inputs are handled, how outputs are generated, and how the system responds when something goes wrong. They are not a single feature or tool, but a collection of controls that operate across the LLM lifecycle.
To understand guardrails clearly, it helps to separate them from concepts:
- Model training and fine-tuning define what a model can do.
- Prompt engineering influences how a model responds in a given interaction.
- Guardrails determine what a model is allowed to do, how its responses are checked, and what happens when boundaries are crossed.
Core types of LLM guardrails
Most LLM guardrail systems fall into three broad categories:
Input guardrails: These validate and filter user inputs before they reach the model. Common examples include intent classification, prompt injection detection, profanity or policy filtering, and sensitive data recognition.
Output guardrails: These evaluate model responses before they are delivered to users or downstream systems. Output guardrails may check for factual consistency, policy compliance, hallucinations, toxicity, bias, or structural correctness.
Behavioral and system guardrails: These govern how the model interacts with tools, APIs, and workflows. They limit actions, enforce roles, apply rate limits, and trigger fallbacks or human review when confidence is low.
Popular guardrails for LLMs
The most widely adopted LLM guardrails frameworks today reflect different design philosophies, ranging from cloud-native governance controls to output validation and evaluation-focused approaches.

Amazon Bedrock guardrails: They are designed for organizations building LLM applications on AWS-managed foundation models. These guardrails operate as a managed control layer that enforces content filtering, topic restrictions, and sensitive data protection across supported models.
NVIDIA NeMo guardrails: They focuses on conversational behavior and policy enforcement, particularly for enterprise chatbots and AI assistants. It is commonly used alongside large foundation models deployed in customer service, IT support, and internal knowledge systems. Rather than validating individual outputs in isolation, NeMo Guardrails manages how conversations unfold over time.
Guardrails AI: This is an open-source framework centered on output validation and structural correctness. It works with both proprietary and open-source LLMs and is widely used in applications where model outputs must meet strict formatting or content requirements.
Its core strength is enforcing schemas, validating responses against rules, and detecting unsafe or unreliable outputs before they reach downstream systems. Guardrails AI is often adopted by engineering teams building API-driven or workflow-based LLM applications, where incorrect outputs can break systems or trigger costly errors.
TruLens: Its approaches guardrails from an evaluation and observability perspective. Rather than blocking outputs directly, it focuses on measuring model behavior across dimensions such as relevance, groundedness, and hallucination risk.
TruLens is commonly used during development and continuous monitoring phases to understand how LLMs perform in real conditions. It supports feedback loops that inform prompt tuning, guardrail refinement, and data improvements.
Why Do We Need LLM Guardrails?
The need for LLM guardrails becomes obvious once models leave controlled demos and enter production. Unlike traditional software, LLMs do not behave deterministically. The same input can produce different outputs depending on context, prompt phrasing, or model updates.
Nowadays, regulations such as the EU AI Act, sector-specific rules, and expanding privacy laws all require transparency, control, and human oversight. Guardrails provide a systematic way to enforce these requirements, turning abstract compliance obligations into concrete, auditable controls embedded in the AI system itself.
Without guardrails, LLMs tend to fail in predictable ways, including confident hallucinations, inconsistent outputs, data leakage, regulatory violations, and exposure to adversarial manipulation, which often forces teams to limit scope or keep systems internal and ultimately reduces ROI.
Rather than constraining capability, well-designed LLM guardrails enable safe customer-facing deployments, regulated use cases, and scalable production systems by strengthening risk management, system stability, and user trust.
This shift from ad hoc risk response to proactive governance not only protects trust and brand value but also enables faster innovation, leading teams to be more willing to deploy and experiment when they know failures will be contained rather than catastrophic.
Explore more: What is Trustworthy AI?
How to Implement Guardrails for Large Language Models
Effective guardrails require tradeoffs between safety, usability, latency, and maintainability, and the hardest decisions are often about policy and risk tolerance rather than technology alone.
The following workflow outlines how guardrails are applied in large language model systems.
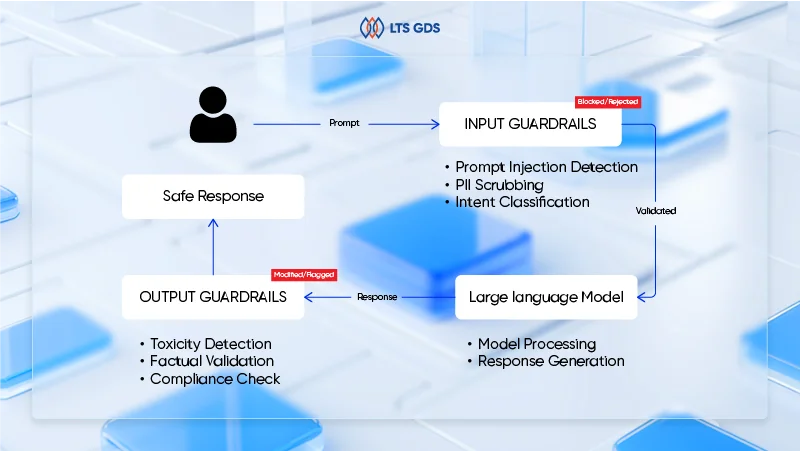
Define safety requirements and risk boundaries
Effective guardrails start with clear definitions of risk, not technology choices. Before any technical implementation, organizations need to determine what the model is allowed to do, where failure is unacceptable, and which regulations, policies, or brand standards apply. These safety requirements will change and update according to different use cases, so it’s necessary for teams to define specific criteria before applying them.
By establishing explicit safety objectives and escalation thresholds early, teams create a shared foundation that guides every downstream decision, from prompt design to validation logic.
Apply input guardrails before model execution
Input guardrails act as the first operational control, filtering and shaping user requests before they reach the model. At this stage, prompts are evaluated for intent, policy alignment, and sensitive information. Common controls include prompt injection detection, intent classification, and PII scrubbing or redaction.
Applying guardrails before model invocation prevents unsafe or unsupported requests from consuming inference resources and reduces the likelihood of harmful outputs later in the pipeline. This step is critical for public-facing or multi-user systems, where adversarial inputs are unavoidable.
Validate outputs before delivery
Once the model generates a response, output guardrails detect whether that response is safe to deliver. This validation layer checks for issues such as hallucinated facts, policy violations, inappropriate tone, or non-compliant content. Responses that fail validation can be blocked, revised, regenerated, or escalated to human review depending on severity.
This step ensures that even when the model behaves unexpectedly, unsafe content does not reach end users or systems.
Continuously monitor and improve guardrails
Guardrails are not static controls. Because large language models undergo ongoing optimization, user behaviors shift, and new risks emerge, guardrails must be constantly reviewed and refined. Logging, monitoring, and feedback loops enable teams to identify failure patterns, update validation rules, and improve training and evaluation datasets over time.
Organizations that treat guardrails as a living system rather than a one-time implementation are better positioned to scale LLM deployments safely and sustainably.
FAQs about LLM Guardrails
What’s the difference between LLM guardrails and content moderation?
Content moderation often operates after content is published or shared, reviewing it for policy compliance and taking action retrospectively. Guardrails intercept and evaluate content in real-time before it reaches end users, making accept-or-reject decisions during the interaction itself. Besides, guardrails also tend to address a broader range of concerns beyond just offensive content, including accuracy, consistency, privacy, and domain boundaries.
Can guardrails completely prevent LLM hallucinations?
No. Hallucination detection represents one of the hardest problems in AI safety because it requires determining factual accuracy, which often demands external knowledge sources and complex reasoning. LLM guardrails can reduce hallucination rates through several mechanisms, requiring citation of sources, validating against knowledge bases, and flagging uncertain responses, but cannot eliminate the problem entirely. Thus, effective strategies combine guardrails with other approaches like retrieval-augmented generation and human-in-the-loop verification for high-quality outputs.
How much do LLM guardrails impact response latency?
It depends significantly on implementation choices. Lightweight rule-based filters add minimal overhead, typically 10-50 milliseconds. ML-based classifiers might add 100-300 milliseconds, depending on model size and infrastructure. LLM-based guardrails that use another AI model to evaluate outputs can add 1-3 seconds. The impact compounds when multiple guardrail layers run sequentially. For many applications, the safety benefits justify some performance cost, but latency-sensitive use cases may need careful optimization.
Should we build custom guardrails or use existing frameworks?
Most organizations benefit from a hybrid approach. Established frameworks provide battle-tested implementations of common safety checks, including toxicity detection, PII filtering, and basic policy enforcement, which would be expensive and time-consuming to replicate. They also benefit from community contributions and ongoing improvements. However, domain-specific requirements almost always demand custom components. Start with frameworks for foundational capabilities and invest custom development effort where it creates a competitive advantage or addresses unique requirements.
How do we measure guardrail effectiveness?
Effective measurement requires tracking multiple dimensions simultaneously. Safety metrics include block rates by category, false negative rates (harmful content that escaped), incident counts, and time-to-detection for issues. User experience metrics cover false positive rates (legitimate content incorrectly blocked), task completion rates, user satisfaction scores, and support ticket volumes. Operational metrics track latency, error rates, and infrastructure costs. The challenge lies in balancing these sometimes-conflicting signals. A guardrail configuration that maximizes safety might devastate user experience, while optimizing for user satisfaction might accept unacceptable risk. Dashboards that visualize tradeoffs across dimensions support more nuanced decision-making than any single metric.
Building Trustworthy Models Starts with LLM Guardrails
LLM guardrails are redefining how organizations move from experimental AI to systems that can be trusted in real production environments. They are not an optional safety layer, but a foundational capability that enables scale, compliance, and long-term adoption.
Effective guardrails work best when they are built on a strong data foundation. High-quality, well-labeled training and evaluation data directly shape how LLMs behave, how reliably guardrails detect failures, and how well systems handle edge cases. When models and regulations transform, organizations that invest early in data quality and structured validation gain a durable advantage in both safety and performance.
If you are building or scaling LLM-powered products, guardrails should be designed alongside your data strategy, not after deployment. Partnering with experienced data labeling teams who understand domain language, risk situations, and quality assurance helps ensure your LLMs operate safely and smartly.
Learn more: A Guide to Data Labeling for Fine-tuning LLMs



