



Software development has always had a productivity playbook. For most of the past decade, the gains came from better frameworks, cleaner abstractions, and DevOps pipelines. Then generative AI arrived and rewrote the autocomplete experience. Developers got faster at typing code they already knew how to write.
In 2026, the tools doing interesting work aren’t finishing your sentences anymore. They read your entire repository, break down a task you described, write the code, run the tests, hit a failure, figure out why, and try again. The question enterprises were asking two years ago: “Should we be using AI for coding?”, has already been replaced by a harder one: which agents do we actually trust in our pipelines, and how do we measure that?
Agents aren’t just faster autocomplete. They take goals, make decisions, use tools, and produce outcomes across multiple files without step-by-step instruction. In some teams, they handle work that used to go to junior engineers. In more mature setups, they operate closer to a collaborative peer.
This guide covers how these agents work, which tools currently lead the market, what the benchmarks actually measure, and where the category is headed.
Introduction to AI Coding Agents
AI coding agents are autonomous software systems built on top of large language models that can understand development objectives, decompose them into structured plans, interact with tools, write and modify code across repositories, execute that code, and iteratively improve their output until the defined goal is achieved.
This is a meaningful departure from earlier generations of AI coding assistants. A conventional AI assistant for coding typically operates at the level of next-line prediction or localized code suggestions. It analyzes the immediate context in an IDE and proposes likely continuations. While useful, this paradigm remains reactive and narrow in scope. The human developer still defines every step of the workflow, manually runs tests, debugs errors, and integrates components.
AI coding agents, by contrast, operate with goal-oriented reasoning. When given a prompt such as “build a RESTful API with authentication and database integration” or “refactor this microservice to improve performance and add test coverage,” the agent does not simply generate a code snippet. Instead, it interprets the objective, formulates a multi-step plan, inspects relevant files in the repository, determines dependencies, writes or modifies code, runs tests, identifies failures, and adjusts its approach.
In practical terms, this means AI agents for coding function less like autocomplete engines and more like junior developers who can execute defined tasks under supervision. They still require oversight, especially in production environments, but they dramatically reduce the manual overhead associated with repetitive or well-structured engineering tasks.
Structurally, AI coding agents function as a “system of systems”: a foundation model handles language and code generation, while a planning layer breaks down complex goals. These agents use tool-use modules to interact with compilers and file systems, retrieval mechanisms to navigate large codebases, and reflection loops to self-correct and refine their output until the task is complete.
How AI Coding Agents Work
To understand how AI coding agents work, it helps to distinguish them from earlier generations of AI coding assistants. Traditional AI coding tools relied heavily on next-token prediction. They analyzed the surrounding code context and predicted the most likely next sequence. This approach worked well for autocompletion but struggled with multi-file reasoning, architectural planning, or debugging across large repositories.
Meanwhile, AI coding agents are built on top of LLMs enhanced with planning layers, tool-use capabilities, memory systems, and execution environments. At a high level, most AI coding agents operate across five layers:
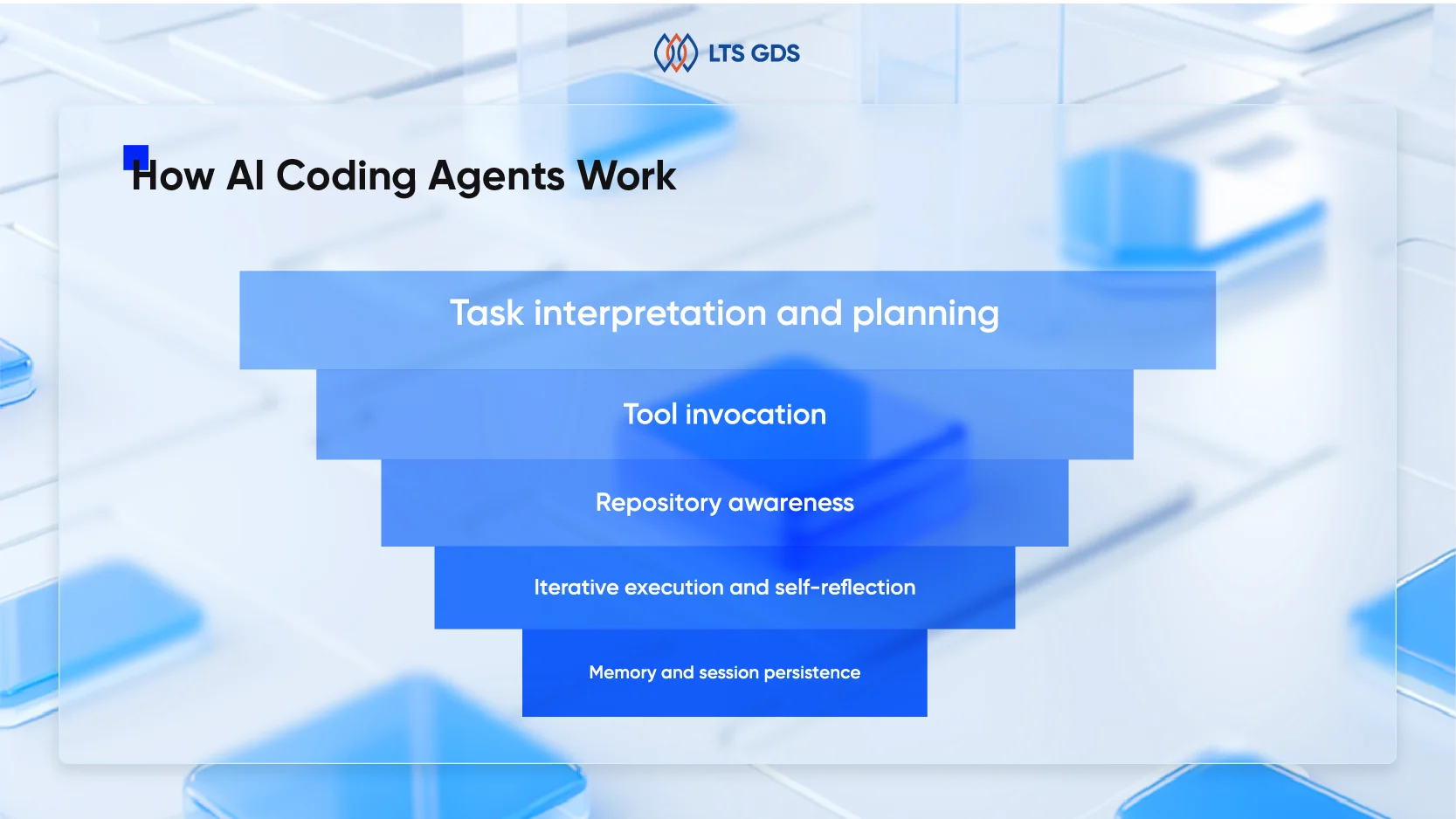
1. Task interpretation and planning
The agent first interprets the user’s objective. Instead of generating code immediately, it often produces a plan. This plan might include reading repository files, identifying dependencies, writing tests, or modifying specific modules. Modern agents use structured reasoning techniques such as chain-of-thought or tree-of-thought planning to break down complex tasks into smaller executable steps.
2. Tool invocation
AI agents for coding do not rely solely on text generation; they interact with tools. These may include code interpreters, shell access, version control systems, test runners, linters, package managers, and API documentation search. The ability to invoke tools transforms an AI coding assistant into a full coding agent. It can write code, run it, observe errors, and self-correct.
3. Repository awareness
Advanced AI coding agents maintain contextual awareness across entire repositories. Instead of processing a few thousand tokens, they use retrieval-augmented generation (RAG) to index codebases and fetch relevant files dynamically. This makes them significantly more effective in enterprise environments with complex legacy systems.
4. Iterative execution and self-reflection
One defining characteristic of top AI coding agents is iterative refinement. They generate code, execute it, review outputs, and adjust. This loop mimics how human engineers debug and refine solutions.
5. Memory and session persistence
Some AI agents maintain session-level memory or persistent project context. This allows them to track architectural decisions over time, improving consistency across tasks.
From a data perspective, the performance of these systems depends heavily on training datasets. High-quality code annotation, bug-fix pairs, repository-level reasoning data, and reinforcement learning from human feedback (RLHF) are critical to improving agent reliability.
Popular AI Coding Agents
By 2026, the AI coding agents landscape will include both embedded IDE assistants and fully autonomous development agents. Below are some of the most widely adopted and discussed systems.
GitHub Copilot
Originally launched as an AI coding assistant, GitHub Copilot has evolved into a more agent-like system with chat-based task execution and repository-wide context analysis. Integrated deeply into developer workflows, it remains one of the most popular AI coding agents globally.
Its strengths lie in seamless IDE integration, strong code completion quality, and enterprise security features. However, its autonomy level is still more limited compared to fully autonomous coding agents.
Claude Code
Claude Code is Anthropic’s AI coding agent designed to operate directly within the development workflow. It goes beyond inline suggestions by handling multi-file edits, refactoring tasks, debugging, and terminal-aware operations. Positioned between IDE assistant and autonomous agent, Claude Code emphasizes reasoning-heavy tasks, long-context code understanding, and safer execution aligned with enterprise guardrails.
Gemini Code Assist
Gemini Code Assist is Google’s AI-powered coding agent built on Gemini models and integrated directly into IDEs such as VS Code and JetBrains. It combines contextual code completion, natural language chat, multi-file edits, and automated code review capabilities, with strong integration across Google Cloud environments. For teams operating within the Google ecosystem, it represents one of the more enterprise-ready AI agents for coding in 2026.
Cursor
Cursor represents a new wave of AI-first IDEs. Instead of embedding AI into traditional editors, Cursor builds the development workflow around AI. It supports codebase-wide modifications and multi-step reasoning.
Among discussions about the best AI coding agents in 2026, Cursor frequently appears due to its deeper agentic capabilities.
What Are the Benefits of Using AI Coding Agents?
Raw speed on individual tasks is real. Studies from multiple organizations have found that developers using AI coding agents complete well-defined, isolated tasks significantly faster than those without. It’s overstated for complex refactoring, debugging distributed systems, or making design decisions where the constraints aren’t obvious.
The more interesting productivity benefit is on the tasks developers avoid doing because they’re tedious rather than difficult. Writing unit tests for code that already works. Adding docstrings to a function. Converting a data structure to a different format. Generating boilerplate for a new service. These are tasks that engineers know how to do and don’t learn from doing, which is just friction. Thus, AI agents handle them well and handle them fast, which means engineers spend more of their time on the work that actually requires judgment.
Code quality is a benefit that gets less attention than speed but matters more over time. A good agent running in review mode will catch error handling gaps, missing edge cases, inconsistent naming, and potential security issues that a developer in a hurry might skip. It’s not a replacement for real code review, but it’s a reliable first pass that improves the signal-to-noise ratio of the review process.
Knowledge accessibility is another underrated benefit. Senior engineers carry institutional knowledge about why a certain module is structured the way it is, about which third-party APIs have known gotchas, and about the project’s style conventions. Some of that knowledge is in documentation, but a lot of it isn’t. A coding agent that’s been given good context can give a junior developer a useful answer to “why does this code do it this way” that would otherwise require interrupting a senior engineer’s focus.
What Makes the Best AI Coding Agents?
With so many options available, what are the best AI coding agents? The answer depends on the use case, but several characteristics define top performers. The best AI coding assistant is not just accurate at code completion. It must demonstrate reasoning depth, contextual awareness, security compliance, and low hallucination rates.
Autonomy is another key dimension. Some tools remain reactive; others proactively plan and execute workflows.
Enterprise readiness also matters. Data privacy controls, audit logs, on-prem deployment options, and secure training pipelines are critical for C-level decision-makers.
Perhaps most importantly, data quality defines agent capability. Without curated, domain-aware code annotation and high-quality evaluation datasets, AI coding agents plateau quickly.
For organizations building custom agents, investing in high-fidelity code labeling, bug-resolution datasets, and repository-level QA loops is essential.
Benchmarks for AI coding agents
Public benchmarks like SWE-bench, HumanEval, and LiveCodeBench give you a starting point, but they answer a narrower question than most enterprise teams need answered. A high SWE-bench score tells you the model can resolve well-defined Python issues from open-source repositories. It doesn’t tell you how the agent behaves in your codebase, with your stack, under your constraints. Structured internal evaluation is what closes that gap. When building an evaluation framework, six dimensions tend to matter most in practice.

Setup covers how much configuration the agent needs before it’s useful, whether it can orient itself in an unfamiliar repository quickly, or requires significant scaffolding before producing reliable output.
Cost is the inference and licensing expense per task, which scales fast in production. An agent that’s 15% more accurate but three times more expensive may not be the right choice for high-volume, lower-stakes work.
Quality is the core output measure: does the code run, does it pass tests, does it handle edge cases, and does it avoid introducing security issues or regressions elsewhere? This is where metrics like pass@k, unit test pass rate, and bug-fix success rate live.
Context measures how well the agent understands the broader codebase beyond the immediate task, whether it respects existing patterns, avoids breaking interfaces defined in other files, and reasons accurately about dependencies it wasn’t explicitly pointed to.
Integration reflects how cleanly the agent fits into your existing workflow: IDE support, version control compatibility, CI/CD hooks, and how well it handles the review and approval process your team already uses.
Speed is iteration latency. Fast feedback loops matter for interactive editing. For longer autonomous tasks, throughput per hour matters more than single-query response time.
Specialization captures domain fit, whether the agent has meaningful knowledge of your specific frameworks, internal APIs, or industry constraints, or whether it’s a generalist tool treating your codebase like any other.
No single benchmark covers all six. The organizations getting the most reliable signal run task-based internal evaluations across a representative sample of real work, treat agent evaluation the way they treat model monitoring in production ML systems, and revisit it regularly as both the tools and their own workflows evolve.
The Future of AI Coding Agents
By 2026, AI coding agents will change from supportive assistants into collaborative, semi-autonomous contributors within engineering teams. The next phase of development is shaped by several structural trends:
Deeper multi-agent orchestration: Engineering teams are increasingly deploying specialized AI agents for distinct functions such as frontend development, backend architecture, security auditing, and automated testing. These agents operate under a supervisory or coordinating layer, enabling parallel task execution and more complex project management.
Domain-specific fine-tuning: Organizations in sectors such as healthcare, fintech, and autonomous systems are training AI agents for coding on industry-specific repositories. This specialization improves compliance alignment, architectural consistency, and task accuracy within regulated or technically complex environments.
Expanded regulation and governance frameworks: AI-generated code becomes mainstream, and enterprises are investing in compliance monitoring, auditability mechanisms, and secure deployment standards to manage legal, security, and operational risks.
Hybrid human-AI engineering models: Rather than replacing developers, AI coding agents amplify senior engineering talent. Human engineers increasingly focus on system architecture, strategic oversight, validation, and complex problem-solving, while agents handle structured execution tasks.
Rising demand for high-quality training data: For AI agent companies and data labeling providers, this evolution significantly increases the need for structured reasoning datasets, execution traces, bug-fix annotations, and real-world code review feedback to enhance agent reliability and reduce hallucinations.
Learn more: Our Data Labeling for Coding LLM

FAQs about AI Coding Agents
What’s the difference between an AI coding agent and an AI coding assistant?
An AI coding assistant reacts to what you’re currently writing by suggesting code inline, answers questions about specific snippets, and operates within the scope of your current editing context. An AI coding agent takes goals rather than prompts, uses tools to take action (read files, run tests, make changes), and can work across a codebase over multiple steps without constant guidance. The line between them is blurring as assistants get more agentic capabilities, but the distinction in how you interact with them and what you can delegate to them is still meaningful.
Do AI coding agents understand any codebase?
Not all of it, not all at once. Every agent has a context window constraint, and even with a large window, fitting a large codebase entirely into context on every query isn’t practical. The better tools use codebase indexing and retrieval to surface the most relevant parts of the codebase for a given task. The quality of that retrieval has a direct impact on output quality. When you’re evaluating tools, testing them on tasks that require understanding relationships between files in different parts of your project is more informative than testing on isolated function-writing tasks.
Are AI coding agents reliable enough to run without human review?
For production code, no or not yet, and probably not in the near term. The current generation is reliable enough to reduce review time significantly, not to eliminate it. The appropriate deployment model is an agent that generates and validates changes, with a human reviewing and approving before anything merges. Fully autonomous deployment pipelines powered by coding agents exist in specific, tightly constrained use cases, but the error rate at which they operate isn’t yet acceptable for most production systems.
AI Coding Agents in 2026: Key Takeaways
AI coding agents have moved beyond experimental tooling and are quickly becoming core infrastructure for modern software development. In 2026, they are embedded in how teams design, build, test, and ship products.
The real competitive edge will not come from adopting the most popular AI coding agents, but from benchmarking them rigorously, fine-tuning them with domain-specific data, and integrating them responsibly into secure engineering workflows. AI agents for coding become more autonomous, organizations that invest in high-quality data annotation, and structured evaluation frameworks will define the next wave of software innovation.
AI coding agents are not just productivity tools; they are collaborative systems shaping the future of engineering. Partner with LTS GDS to develop high-quality data labeling pipelines for coding LLMs and agentic AI systems, allowing your AI coding agents perform effectively in real production environments.



