



Client overview
Our client is a research group at a leading U.S. technology university. They are developing an AI Agent in the form of a Computer Use Agent (CUA), capable of interacting with and operating across platforms on macOS, Windows, and Linux. At the current stage, the agent can analyze requests, translate them into goals, and execute the corresponding tasks.
Business Challenges
- Requires a very large, high-quality trajectory dataset for stable and generalizable CUA learning.
- Struggles are common with complex, stateful UI components (e.g., select boxes, editable fields, modals).
- Tasks must stay diverse and increase in complexity as the model evolves.
- Near-perfect step accuracy and strict QC are needed—one wrong step can invalidate the entire outcome.
- Must cover macOS, Windows, and Linux to avoid OS-specific failures due to UI/behavior differences.
- Needs scalable, high-skill resourcing while keeping cost efficient.
- Requires reliable benchmarks to track progress and align training with evaluation criteria.
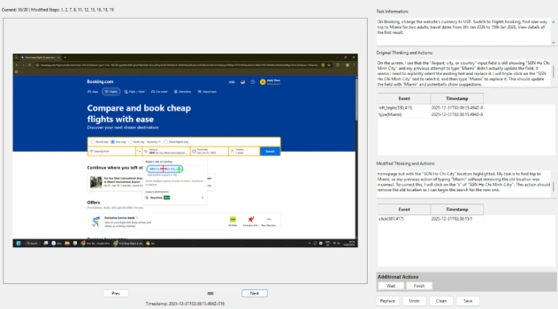
Project Detail
Trajectory Collection & Recording, Task Authoring & Scenario Design, Multi-OS Generalization, OSWorld-based Environment & Evaluation Harness, Benchmark Construction & Protocol, AI Evaluation, Modified Thinking, Data Governance
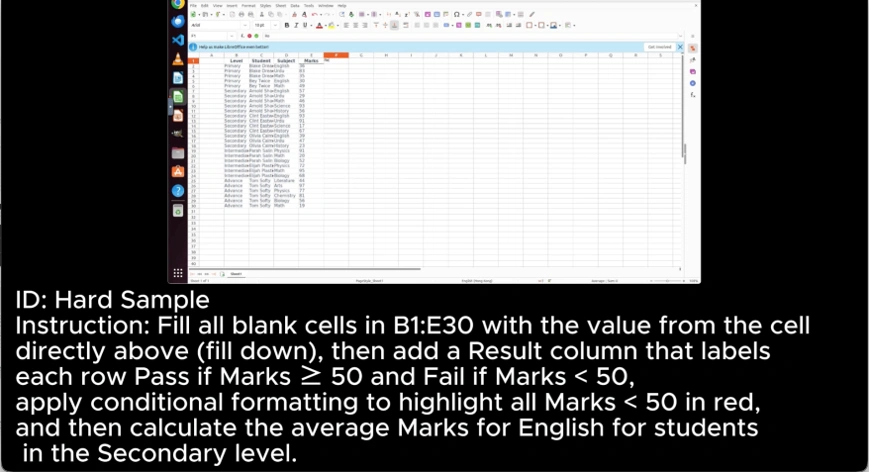
Solutions
1.Operate a standardized recording + revision pipeline with experienced operators to deliver high throughput.
2.Proactively design scenarios targeting known failure modes and hard UI interactions to improve coverage where models break.
3.Maintain a flexible task-generation pipeline aligned with the model roadmap for fast task refresh and difficulty ramp-up.
4.Implement end-to-end QA with clear rubrics, multi-layer checks (peer review, spot checks, gold standards), and metrics tracking (success rate, lead time, self-recovery).
5.Standardize cross-OS guidelines and execute tasks across all three platforms to reflect deployment conditions and reduce OS-specific errors.
6.Scale capacity through a proven outsourcing model with rapid training, performance measurement, and competitive cost.
7.Build benchmark task suites that balance difficulty and discriminability, reflect real-world workflows, and provide actionable signals for iteration.



