Ryan Le
Gen AI Manager
Coding, STEM & Engineering, Physical AI & Robotics




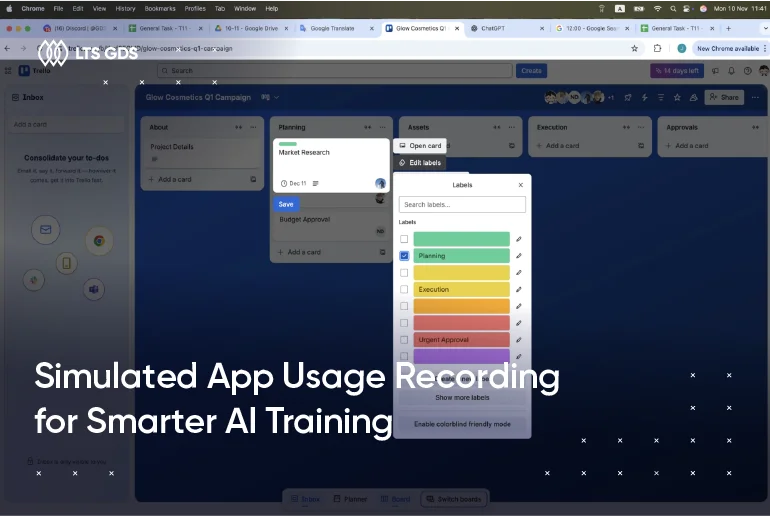
 LTS GDS delivers high-quality supervised datasets to adapt pre-trained LLMs into domain-specific, task-oriented systems across various industries.
LTS GDS delivers high-quality supervised datasets to adapt pre-trained LLMs into domain-specific, task-oriented systems across various industries.
Our offerings include:

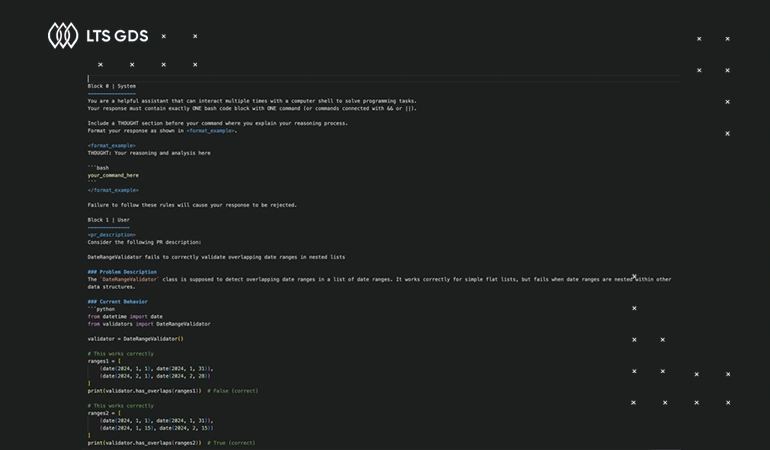
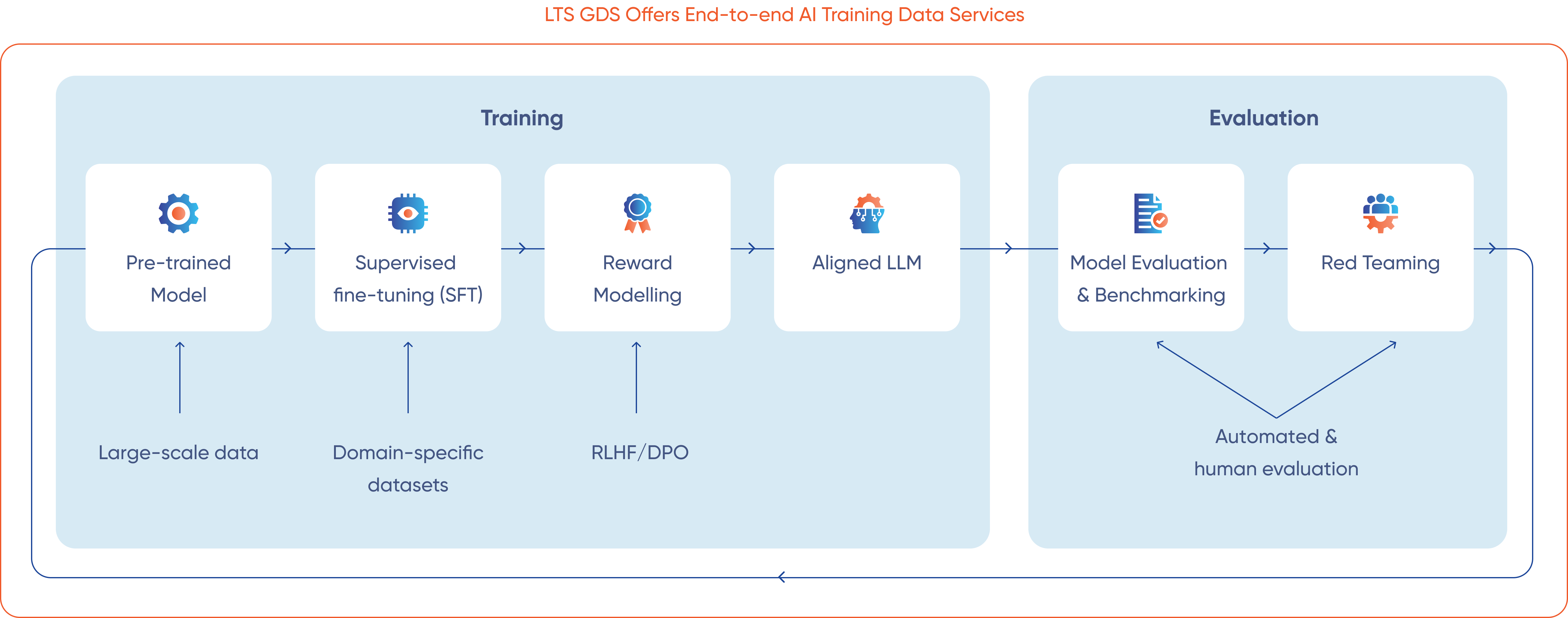
We design structured instruction datasets that improve model reasoning, task understanding, and output consistency across complex scenarios.
Several tasks we focus on:

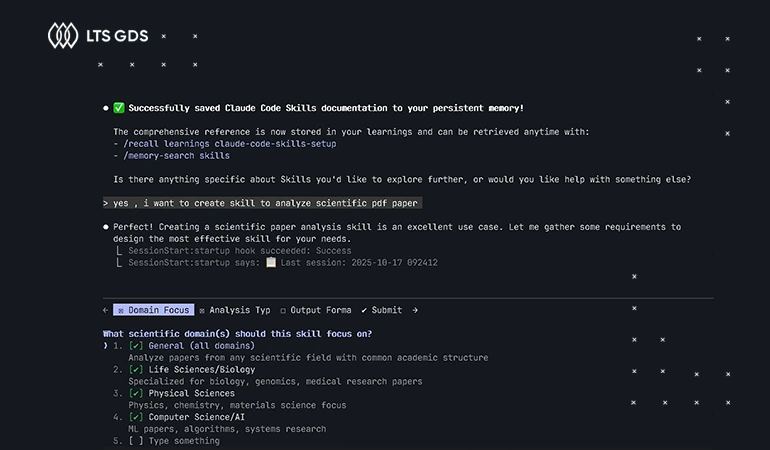
Our experts evaluate model-generated responses in different contexts using reinforcement learning with human feedback (RLHF) and Direct Preference Optimization (DPO).
Key features:

We improve model safety and compliance through targeted datasets that reduce hallucinations, bias, and deployment risks.
What we deliver:


Vietnamese

English

Russian

Mandarin Chinese

Cantonese

Japanese

Korean

Malay

Indonesian

Thai

Lao

Hindi

Arabic

French

German

Spanish

Portuguese

Italian

Bulgarian

Hungarian
Engineering
Civil Engineering
Law
Finance
Accounting
Economics
Mathematics
Computer Science
Medicine
Psychology
Physics
Healthcare
Chemistry
Biology
Astronomy
Biotechnology
Bioinformatics
Teaching
Linguistics
Religion
Language Arts
Music
Philosophy
History
Performing Arts
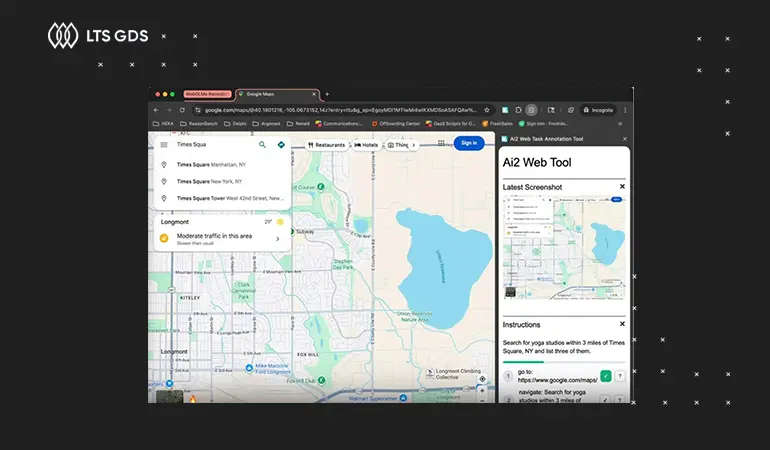
Robotics Engineers
Computer Scientists
Software Engineers
Systems Architects
Data Engineers
AI/ML Researchers
Financial Analysts
Accountants
Auditors
Economists
Investment Bankers
Risk Managers
Psychologists
Sociologists
Political Scientists
Administrators
Scientists
Mathematicians
Photographers
Screenwriters
VFX Supervisors
Cinematographers
Art Directors
Creative Directors
Animation Directors
3D Modelers
Sound Designers
Audio Engineers
Music Composers
Voice Directors


A dedicated project manager works closely with the client to understand business objectives, data sources, and LLM fine-tuning needs. We assess model scope, domain requirements, training methods, compliance considerations, expected outcomes, and cost factors. Based on this, we propose a customized LLM fine-tuning strategy to ensure alignment before project initiation.

LTS GDS will assemble a dedicated delivery team, including both internal experts and vendor partners from different regions worldwide when needed. Training sessions are conducted to align all team members on project goals, annotation or data preparation quality standards, and execution methodology. This ensures every contributor understands the LLM fine-tuning workflow from day one.

Before scaling, our team executes trial tasks to validate the process. Outputs are shared with the client for review, and feedback is integrated into updated guidelines. This step helps refine edge cases, improve consistency, and ensure the LLM fine-tuning process matches business objectives.

LTS GDS manages large-scale LLM fine-tuning with strict deadlines and regular quality checks. Specialized teams handle different tasks, while ongoing meetings ensure the training process adapts to client feedback. Together with our clients, LTS GDS defines clear evaluation criteria to measure output quality and refine results until they meet expectations.

We proactively track and report issues, such as unclear requirements or hidden scenarios, to the client. Our internal team meets regularly to resolve errors, update workflows, and strengthen the LLM fine-tuning outcomes over time.










We deliver reliable LLM fine-tuning outcomes with high accuracy. Our multi-layered review process ensures that models are refined with critical thinking and contextual understanding.

Our AI trainers bring deep knowledge across industries to create domain-specific LLMs that understand specialized terminology and meet real model needs.

With huge teams in many regional markets and cultures, our experts train LLMs that adapt naturally to multilingual use cases and cultural nuances.
Leverage Vietnam’s competitive labor costs, favorable business environment, and flexible pricing models to optimize your LLM projects.