Supervised Fine-Tuning (SFT)
Human Preference Ranking (RLHF)
LLM Evaluation & A/B Testing
LLM Red Teaming
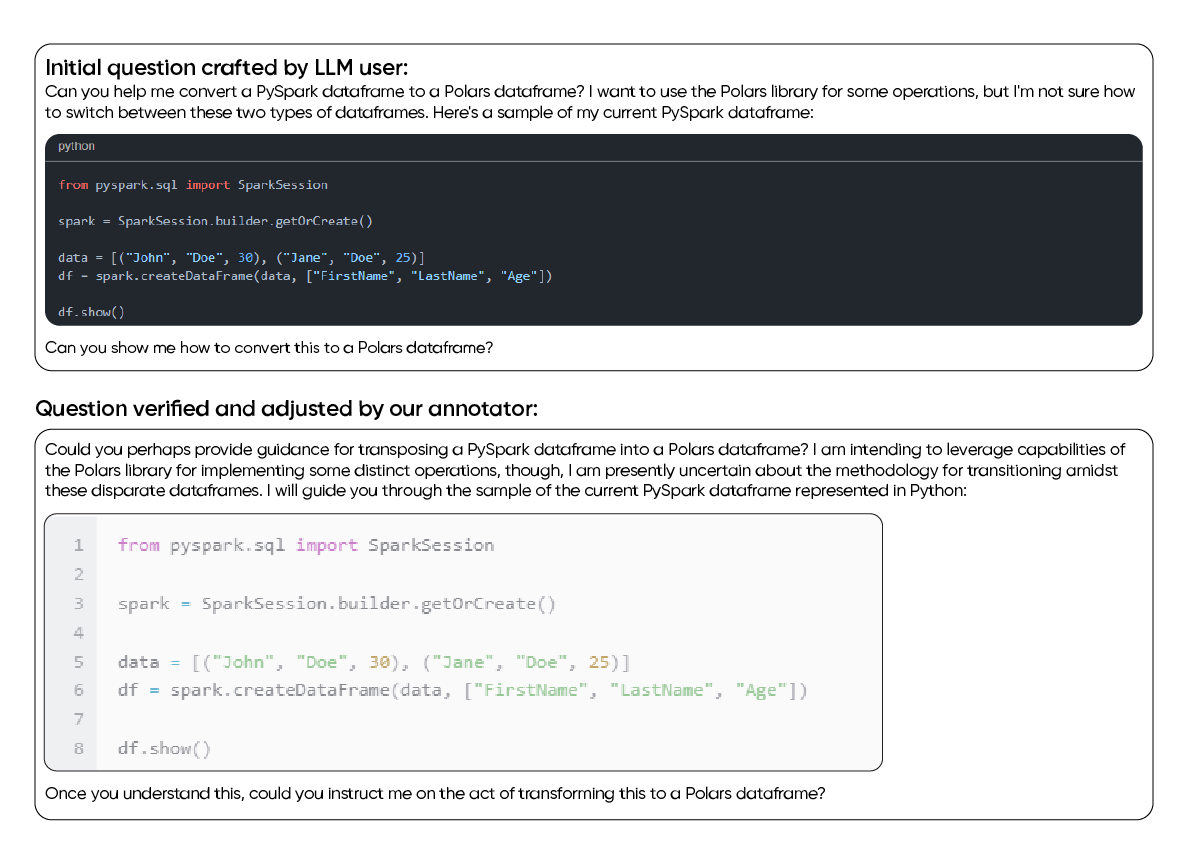
- Prompt generation.
- Prompt verification.
- Answer generation.
- Answer verification.
- Dialogue generation.
- Dialogue evaluation.
- Bug detection and fix suggestions.
- Real-time human interactions.
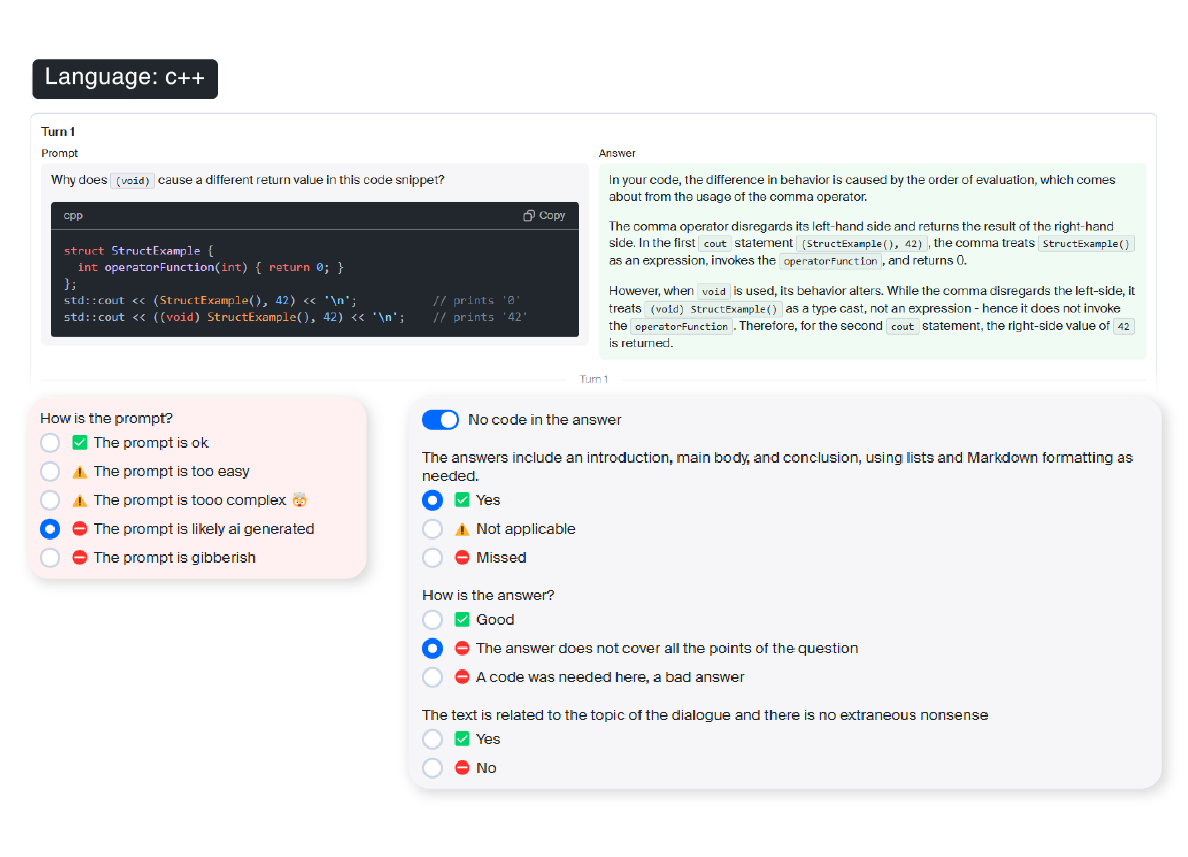
- Evaluation of single- or multi-turn conversations.
- Customizable evaluation criteria: semantic accuracy, syntax compliance, performance optimization, and more.
- Detailed comparisons between code generation models.
- Evaluation based on correctness, performance, and coherence.
- Support for both qualitative and quantitative analysis of model responses in specific programming scenarios.
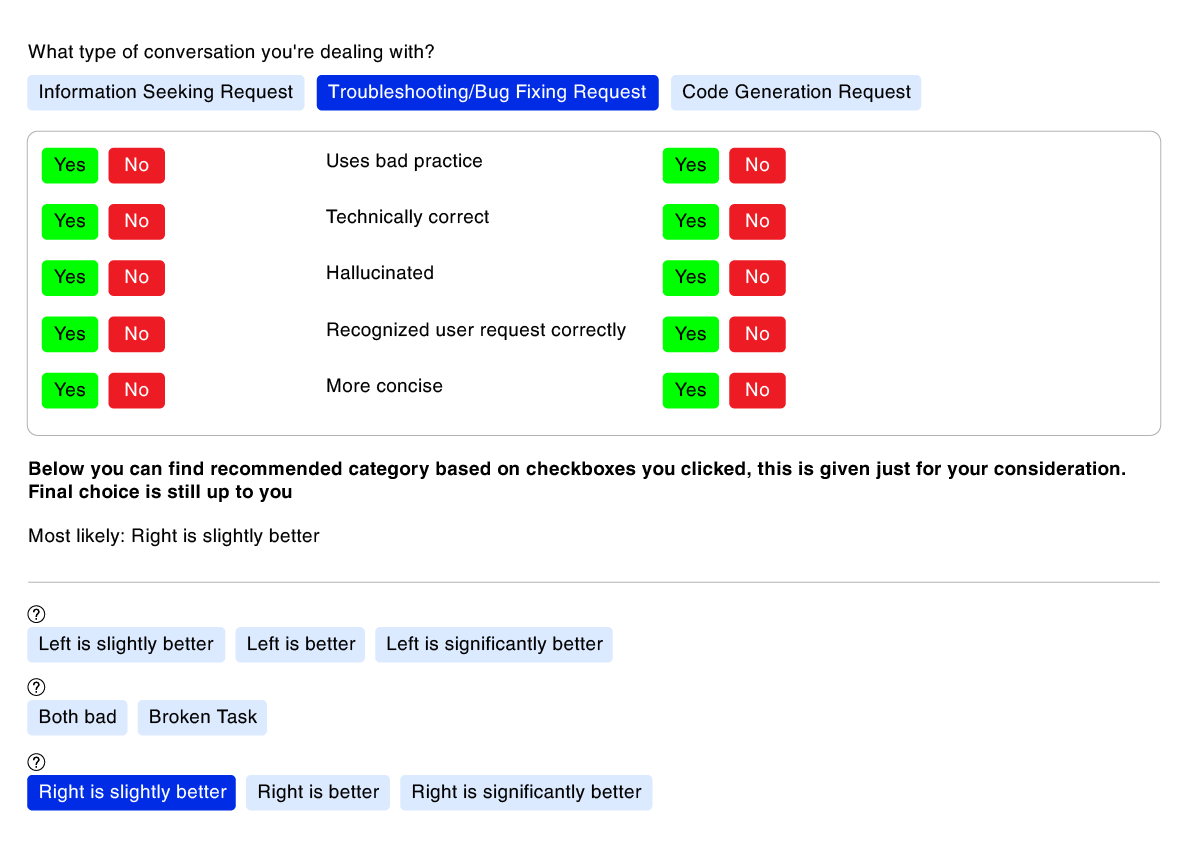
- Insecure code generation.
- Malicious or inappropriate suggestions (e.g., bypassing authentication, SQL injection).
- Multi-turn testing using real-world scenarios.




We begin by setting up the project team, including both internal and vendor teams, and then assign tasks based on the required programming languages. We conduct training sessions for both our delivery team and vendors to clarify guidelines and answer questions. Finally, we hold meetings with both teams to align on the execution methodology.

We carry out trial tasks and deliver them to the client. After receiving feedback, we organize follow-up meetings with internal and external delivery teams. Based on the results and feedback, we update the guidelines to address new scenarios or edge cases identified during this phase.

- If a batch achieves a ≥90% acceptance rate, the entire batch is approved.
- If a batch has a ≥90% rejection rate, the entire batch must be reworked and resubmitted.

We report externally caused rejections (unclear descriptions, hidden requirements) to the client for clarification. Additionally, we meet every other day to address and resolve internal errors discovered during the execution process.

Superior Quality
Rigorous QA processes are implemented to build precise Supervised Fine-tuning (SFT) datasets with up to 99% accuracy, specifically designed for training high-performing coding models.

Proven Expertise
100+ seasoned developers mastering in SQL, Python, C#, JavaScript, TypeScript, Bash, .NET, Scala work tirelessly to ensure LLMs generate code fast, logical and bug-free.

Quick Team Ramp-up
LTS GDS guarantees to build up a dedicated team consisting of a battle-hardened PM and up to 200 man-months from in-house team and our partner network for large-scale projects within 2 weeks.

Cost-effectiveness
Global businesses can get IT experts to adapt pre-trained models to coding-specific LLMs with optimal budgets in light of the expense gaps of Vietnam outsourcing market and favorable tax policies.